
Privacy by Design bedeutet, Datenschutz nicht nachträglich anzuflanschen, sondern von Anfang an in die Softwarearchitektur einzubauen. Bei QUALLEE umfasst das: granulares Consent-Management mit Audit-Trail, automatische Datenlöschung nach definierten Speicherfristen, Self-Service für Betroffenenrechte und vollständige Transparenz bei KI-Verarbeitung. Dieser Artikel zeigt die konkrete technische Umsetzung.
Warum Datenschutz Architektur ist
Die meisten Softwareprodukte behandeln Datenschutz wie eine Checkliste, die man kurz vor dem Launch abhakt. Cookie-Banner hier, Datenschutzerklärung dort, vielleicht noch ein Consent-Popup. Fertig.
Bis jemand fragt, wo genau die Einwilligung gespeichert ist. Bis ein Nutzer seine Daten exportieren will. Bis die Aufsichtsbehörde wissen möchte, wie lange welche Daten aufbewahrt werden.
Nachträglicher Datenschutz ist teurer als eingebauter. Das war die Überlegung, als wir QUALLEE gebaut haben. Privacy by Design ist keine Philosophie, sondern eine Architekturentscheidung, die man entweder am Anfang trifft oder später teuer nachbessert.
Die sieben Prinzipien nach Ann Cavoukian
Dr. Ann Cavoukian hat Privacy by Design in den 90ern formuliert. Sieben Prinzipien, die 2010 von den internationalen Datenschutzbehörden als Standard anerkannt wurden. Die DSGVO hat sie in Artikel 25 übernommen.
Die Prinzipien klingen abstrakt: "Proaktiv statt reaktiv", "Privacy als Standardeinstellung", "Ende-zu-Ende-Sicherheit". In der Praxis bedeuten sie konkrete Entscheidungen.
Produktiv statt reaktiv: Das heißt für uns, bevor wir ein Feature bauen, fragen wir uns, welche Daten es braucht und wie lange. Nicht erst, wenn jemand nach der Speicherfrist fragt.
Privacy als Default: Wenn ein Nutzer nichts tut, sind seine Daten trotzdem geschützt. Keine Opt-out-Fallen, keine vorausgewählten Marketing-Checkboxen.
Privacy eingebettet ins Design: Datenschutz ist keine Komponente, die man an- oder ausschalten kann. Er steckt in der Datenbankstruktur, in den API-Endpoints, in den UI-Komponenten.
KI-Produkte und das Vertrauensproblem
KI-Produkte haben ein Imageproblem beim Datenschutz. Die Schlagzeilen über Trainingsdaten, über Modelle, die persönliche Informationen reproduzieren, über undurchsichtige Datenflüsse haben Spuren hinterlassen.
Das Problem ist real, aber kein Naturgesetz. KI-gestützte Produkte können datenschutzkonform sein; sie erfordern nur mehr Sorgfalt bei der Architektur.
Bei QUALLEE fließen Interviewdaten durch KI-Modelle von Anthropic und OpenAI. Das ist der Kern des Produkts. Gleichzeitig haben wir klare Grenzen gezogen.
Die Rohdaten bleiben auf unseren Servern in Deutschland. An die KI-APIs gehen nur die für die Analyse notwendigen Textinhalte, verschlüsselt übertragen. Beide Anbieter haben Data Processing Agreements unterzeichnet, die eine Verwendung für Modelltraining ausschließen. Wir haben die DPAs von OpenAI, Anthropic, Stripe und weiterer Dienstleister dokumentiert und abgelegt.
Die KI analysiert, was Menschen sagen; sie analysiert nicht, wie sie dabei aussehen. Keine Gesichtserkennung, keine Emotionserkennung aus Video oder Audio. Das ist seit Februar 2025 durch den EU AI Act in bestimmten Kontexten ohnehin verboten, aber wir haben es von Anfang an so gebaut.
Consent-Management nach DSGVO Art. 6
Die DSGVO unterscheidet verschiedene Rechtsgrundlagen für Datenverarbeitung. Artikel 6 listet sie auf. Für uns sind zwei besonders relevant: Vertragserfüllung und Einwilligung.
Wenn ein zahlender Kunde den Analysechat nutzt, verarbeiten wir seine Daten auf Basis der Vertragserfüllung. Er hat ein Abo abgeschlossen, die Analyse ist Teil des Vertrags. Ein Hinweis reicht, dass KI zum Einsatz kommt. Kein Modal, kein Häkchen, keine Speicherung.
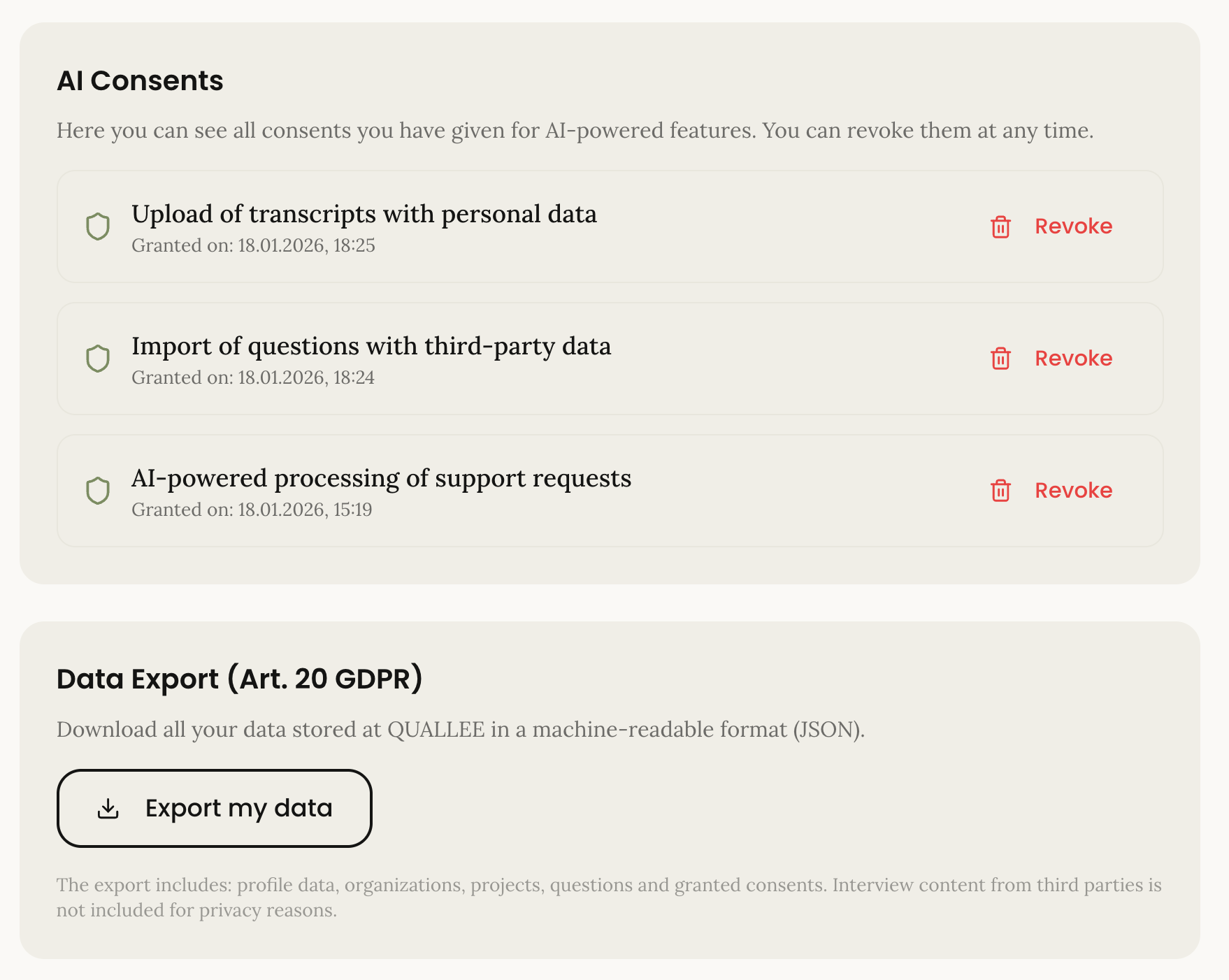
Anders sieht es aus, wenn Daten Dritter ins Spiel kommen. Wenn ein Researcher Transkripte hochlädt, die Aussagen von Interviewteilnehmern enthalten. Oder wenn jemand Kernfragen importiert, die möglicherweise personenbezogene Informationen enthalten. Hier brauchen wir explizite Einwilligung, und wir müssen sie speichern.
Die Unterscheidung klingt akademisch, hat aber praktische Konsequenzen. Ein Info-Hinweis ist ein Satz Text im UI. Eine gespeicherte Einwilligung ist ein Datenbankeintrag mit Zeitstempel, IP-Adresse, User-Agent und Versionsnummer des Consent-Texts.
| Stelle | Was nötig ist | Begründung |
|---|---|---|
| Analysechat | Info-Hinweis | User ist Vertragspartner |
| Supportchat | Info-Hinweis | Vertragserfüllung |
| Kernfragen-Import | Consent + Speicherung | Daten Dritter möglich |
| Transkript-Upload | Consent + Speicherung | Daten Dritter (Interviewees) |
| Interview-Teilnahme | Consent + Speicherung | Teilnehmer ist nicht Vertragspartner |
Technische Umsetzung des Consent-Managements
Consent-Management braucht Infrastruktur. Bei uns sind das zwei Datenbanktabellen, mehrere API-Endpoints und ein React-Hook.
Die Tabelle `UserAiConsent` speichert Einwilligungen von registrierten Nutzern. Jeder Eintrag enthält den Consent-Typ, den Zeitpunkt der Erteilung, optional den Zeitpunkt des Widerrufs, IP-Adresse, User-Agent und die Version des Consent-Texts. Die Kombination aus User-ID und Consent-Typ ist eindeutig; ein Nutzer kann pro Typ nur eine aktive Einwilligung haben.
Die Tabelle `IntervieweeConsent` ist für Interviewteilnehmer. Sie sind keine registrierten Nutzer, haben also keine User-ID. Stattdessen verknüpfen wir den Consent mit der Session-ID. Zusätzlich speichern wir einen SHA-256-Hash des angezeigten Consent-Texts. Damit können wir später nachweisen, welchen exakten Text der Teilnehmer gesehen hat.
Der React-Hook `useAiConsent` macht das Consent-Management im Frontend nutzbar. Er prüft beim Laden der Komponente, ob bereits ein Consent vorliegt. Falls nicht, zeigt er ein Modal. Nach Bestätigung speichert er den Consent über die API und merkt sich den Status für die Session.
```typescript const { hasConsent, grantConsent, showConsentModal } = useAiConsent("import_questions")
// Vor einer Aktion, die Consent erfordert: if (!hasConsent) { setShowConsentModal(true) return } // Consent vorhanden, Aktion ausführen ```
Beim Widerruf löschen wir den Consent-Eintrag nicht, sondern setzen ein `revokedAt`-Datum. Die DSGVO erlaubt es, Consent-Nachweise auch nach Widerruf aufzubewahren; sie sind Teil der Dokumentationspflicht.
KI-Transparenz nach EU AI Act
Der EU AI Act schreibt seit August 2025 vor, dass Nutzer informiert werden müssen, wenn sie mit einem KI-System interagieren. Wir haben das von Anfang an so gebaut.
Der ConsentDialog für Interviewteilnehmer macht unmissverständlich klar, dass ein KI-System das Interview führt. Der Text ist in fünf Sprachen verfügbar: Deutsch, Englisch, Französisch, Spanisch, Italienisch. Keine maschinelle Übersetzung, sondern lokalisierte Texte.
Der Dialog enthält drei zentrale Informationen: Daten werden verschlüsselt auf einem deutschen Server gespeichert. Die Verarbeitung erfolgt durch KI-Modelle. Die Daten werden nicht für KI-Training verwendet.
Zusätzlich zum Consent-Häkchen gibt es eine Captcha-Verifizierung. Das ist keine DSGVO-Anforderung, sondern Schutz vor automatisierten Zugriffen.
Im Dashboard sind KI-Hinweise weniger prominent, aber vorhanden. Ein kleiner Text über dem Chat: "KI-gestützte Analyse". Kein Modal, kein Popup; der Nutzer weiß Bescheid, ohne unterbrochen zu werden.
Automatische Datenlöschung nach Speicherfristen
Speicherfristen festzulegen ist einfach. Sie einzuhalten ist schwerer.
Die DSGVO verlangt in Artikel 5, dass Daten nicht länger aufbewahrt werden als nötig. Das klingt selbstverständlich, scheitert aber in der Praxis regelmäßig. Die Studie ist abgeschlossen, die Daten liegen noch irgendwo, niemand kümmert sich darum.
Wir haben einen Cronjob eingerichtet, der täglich um 02:30 Uhr läuft. Er prüft drei Kategorien: Support-Tickets älter als 24 Monate werden gelöscht. Archivierte Interview-Sessions älter als 12 Monate werden gelöscht. Consent-Nachweise von gelöschten Nutzern werden nach 36 Monaten entfernt.
Der Job läuft im Dry-Run-Modus, wenn man ihn manuell startet. Er zeigt an, was gelöscht würde, ohne tatsächlich zu löschen. Erst mit dem Flag `--execute` werden Daten wirklich entfernt.
| Datentyp | Speicherfrist | Automatische Löschung |
|---|---|---|
| Support-Tickets | 24 Monate | Ja |
| Archivierte Sessions | 12 Monate | Ja |
| Consent-Nachweise | 36 Monate nach Löschung | Ja |
| Projektdaten | Projektlaufzeit + 12 Monate | Bei Projektlöschung |
Betroffenenrechte als Self-Service
Die DSGVO gibt Menschen Rechte über ihre Daten: Auskunft (Art. 15), Berichtigung (Art. 16), Löschung (Art. 17), Datenübertragbarkeit (Art. 20). In vielen Produkten sind das manuelle Prozesse: Der Nutzer schreibt eine E-Mail, jemand exportiert händisch die Daten, schickt sie als ZIP-Datei.
Bei uns sind das Features in den Account-Einstellungen.
Die Privacy-Seite zeigt alle erteilten Consents an. Nutzer können sie einzeln widerrufen. Der Widerruf ist so einfach wie die Erteilung; das verlangt Artikel 7 Absatz 3 der DSGVO.
Der Datenexport erzeugt eine JSON-Datei mit allen personenbezogenen Daten: Kontoinformationen, Projekte, erteilte Consents. Maschinenlesbar, wie Artikel 20 es verlangt.
Die Kontolöschung ist ein Soft-Delete mit Anonymisierung. Wir entfernen personenbezogene Daten, behalten aber anonymisierte Projektdaten, falls sie für andere Teammitglieder relevant sind. Consent-Nachweise bleiben erhalten; das erlaubt Artikel 17 Absatz 3 ausdrücklich.
Was wir daraus gelernt haben
Privacy by Design kostet Zeit. Die Consent-Infrastruktur zu bauen hat länger gedauert als ein einfaches Cookie-Banner. Die automatische Löschung erfordert mehr Planung als "wir löschen, wenn sich jemand beschwert".
Diese Investition zahlt sich aus, nicht primär durch vermiedene Bußgelder (obwohl die DSGVO-Strafen 2025 bei über 2 Milliarden Euro lagen), sondern durch Vertrauen. Researcher arbeiten mit sensiblen Daten. Sie wollen wissen, dass ihre Teilnehmer geschützt sind. Ein nachvollziehbares Datenschutzkonzept ist ein Verkaufsargument.
Der EU AI Act hat die Anforderungen erhöht, nicht geändert. Wer seine KI-Produkte von Anfang an transparent und datensparsam baut, muss im August 2026 nicht hektisch nachbessern.
Häufig gestellte Fragen
Was ist Privacy by Design?
Privacy by Design ist ein Konzept von Dr. Ann Cavoukian, das fordert, Datenschutz von Anfang an in die Entwicklung von Systemen einzubauen, statt ihn nachträglich hinzuzufügen. Die DSGVO hat es in Artikel 25 als "Datenschutz durch Technikgestaltung" rechtlich verankert.
Wie unterscheidet sich Info-Hinweis von explizitem Consent?
Ein Info-Hinweis reicht bei Vertragserfüllung (Art. 6 Abs. 1 lit. b DSGVO), wenn der Nutzer selbst Vertragspartner ist. Expliziter Consent mit Speicherung ist nötig, wenn Daten Dritter verarbeitet werden oder der Betroffene kein Vertragspartner ist.
Wie lange müssen Consent-Nachweise aufbewahrt werden?
Die DSGVO schreibt keine konkrete Frist vor, aber Unternehmen müssen die Einwilligung nachweisen können. Empfohlen werden 3 Jahre nach Widerruf oder Vertragsende, da dies der zivilrechtlichen Verjährungsfrist entspricht.
Werden meine Daten für KI-Training verwendet?
Nein. Sowohl OpenAI als auch Anthropic haben Data Processing Agreements unterzeichnet, die eine Verwendung von API-Daten für Modelltraining ausschließen. Die Rohdaten bleiben auf deutschen Servern.
Selbst ausprobieren
QUALLEE führt KI-gestützte Interviews durch, die von Anfang an datenschutzkonform sind. Deutsche Server, dokumentierte AVVs, automatische Löschfristen, transparente Consent-Prozesse. Ein Interview dauert etwa 20 bis 30 Minuten.
