
QUALLEE kombiniert drei spezialisierte Technologien für die Analyse großer Interviewmengen: eine Vektordatenbank für semantische Suche, einen Knowledge Graph für Beziehungen und Strukturen, und ein Sprachmodell, das nur auf Basis verankerter Daten analysiert. Diese disruptive Architektur ermöglicht es, 20, 50 oder 100 Interviews genauso präzise zu analysieren wie 5 – ohne Halluzinationen, ohne verlorenen Kontext, mit nachvollziehbaren Quellenangaben. Hier erklären wir, wie das funktioniert, ohne zu technisch und abstrakt zu sein.
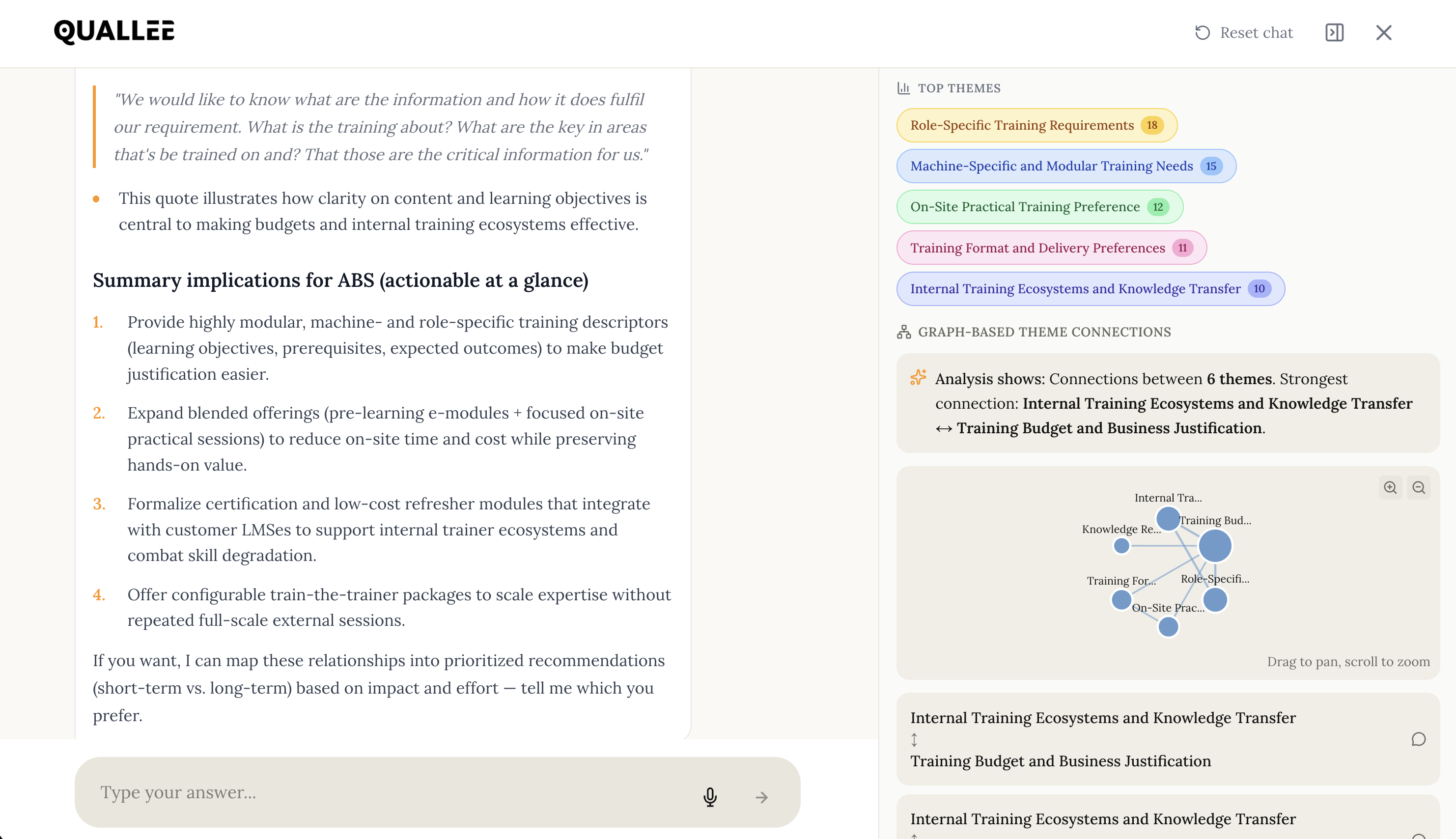
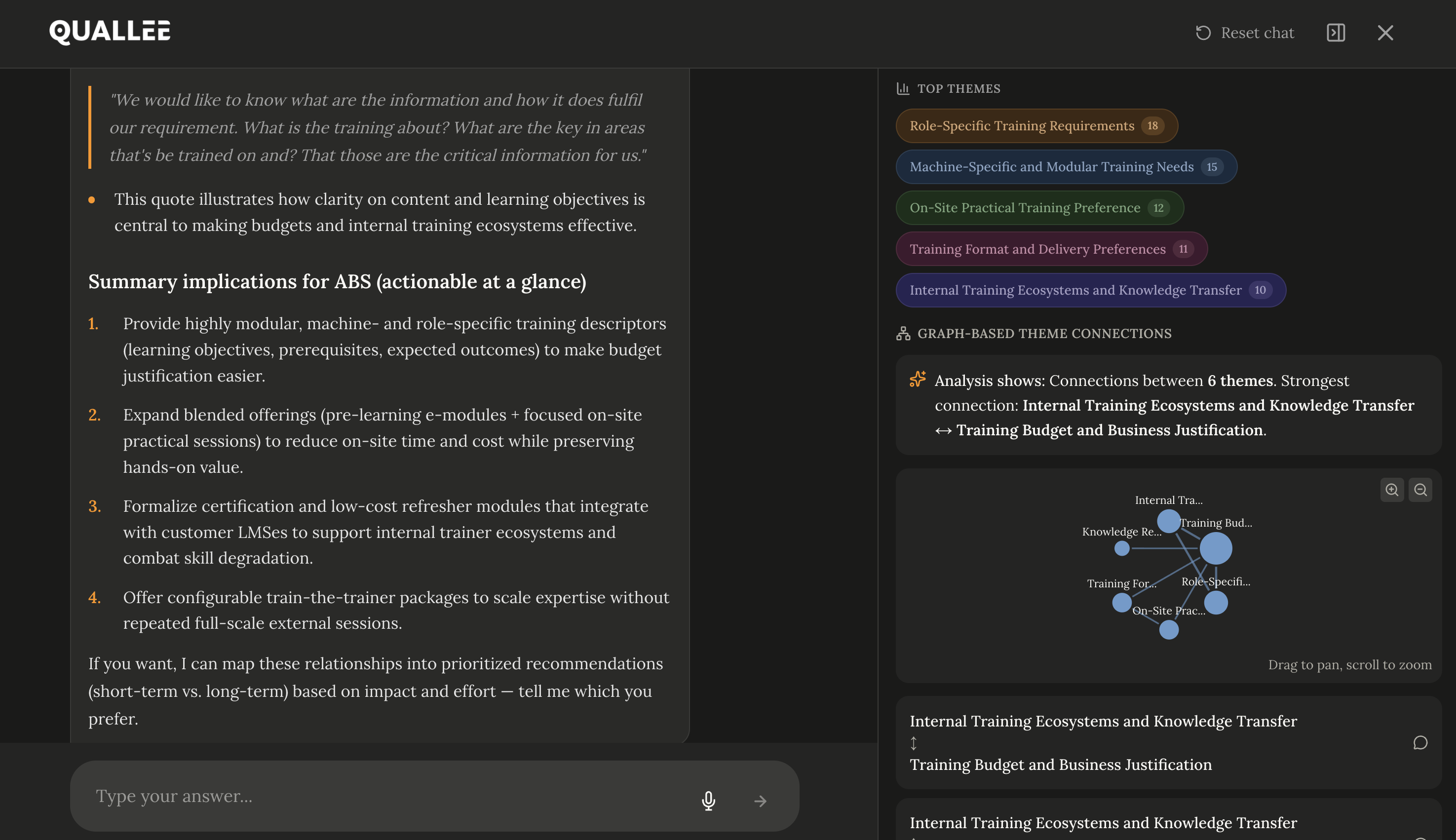
Die Aussage existiert, da bist du sicher. Du hast sie gehört, als du das Interview geführt hast. Irgendetwas über den Moment, in dem die Teilnehmerin fast gekündigt hätte. Jetzt, drei Wochen später, vor 400 Seiten Transkript: keine Chance. Strg+F hilft nicht, weil du dich nicht an das exakte Wort erinnerst. War es "Vertrauen"? "Skepsis"? "Unsicher"? Wahrscheinlich hat sie es ganz anders formuliert.
Das war unser Ausgangsproblem. Nicht nur "wie machen wir qualitative Forschung schneller", sondern: Wie findest du in einem Berg von Transkripten das, was du suchst, ohne die exakten Worte zu kennen? Und wie stellst du sicher, dass die KI, die dir dabei hilft, nicht anfängt, Dinge zu erfinden?
Warum ein einzelnes KI-Modell nicht reicht
Die offensichtliche Lösung wäre, alles einem Sprachmodell wie OpenAIs GPT oder Anthropics Claude zu geben und Fragen zu stellen. Schon bei zwei bis drei Interviews fangen sie an zu halluzinieren. Bei acht oder zwölf bricht es zusammen.
Sprachmodelle haben ein Kontextfenster: die maximale Textmenge, die sie gleichzeitig verarbeiten können. Ein einstündiges Interview ergibt transkribiert etwa 8.000 bis 10.000 Wörter. Bei 40 Interviews landest du bei 400.000 Wörtern. Selbst die größten Modelle mit 200.000 Token Kontextfenster schaffen das nicht, und wenn sie es versuchen, passiert etwas Gefährliches: Sie lassen Wichtiges komplett aus, sie fangen an Dinge zu erfinden. Sie verwechseln Teilnehmer und sehen Muster, die nicht existieren. Und das Schlimme: All das hört sich plausibel, schlüssig und auf den Punkt analysiert an.
Statt alles auf die KI zu werfen könnte man sie die Transkripte vorher zusammenfassen lassen oder das selbst tun. Aber eine Zusammenfassung ist bereits eine Interpretation. Du verlierst die wörtlichen Zitate, die Nuancen, den Kontext. Aber genau das ist es, was qualitative Forschung ausmacht und ihr Relevanz verschafft.
Die drei Systeme und ihre Aufgaben
Wir haben eine Architektur mit drei spezialisierten Technologien gebaut. Jede löst ein anderes Problem. Und zusammen ergeben sie etwas, das keines allein könnte.
Vektordatenbank
Semantische Suche
Findet Bedeutungen, nicht nur Wörter. Erkennt Synonyme wie „frustriert" und „genervt".
Knowledge Graph
Beziehungen & Strukturen
Verbindet Wer mit Was und Wie. Zeigt Zusammenhänge zwischen Themen und Sprechern.
Verankertes LLM
Analyse & Interpretation
Analysiert nur auf Basis verifizierter Daten. Verhindert Halluzinationen.
Die Synergie im Analyse-Chat: Präzision bei jeder Skalierung
Analysiere 20, 50 oder 100 Interviews mit der gleichen Genauigkeit wie fünf.
DSGVO-konformSystem 1: Vektordatenbank – findet Aussagen nach Bedeutung, nicht nach Wörtern.
System 2: Knowledge Graph – speichert, wer was gesagt hat und wie Themen zusammenhängen.
System 3: LLM mit Verankerung – analysiert und interpretiert, aber nur auf Basis dessen, was die anderen beiden liefern.
Das klingt abstrakt. Lass mich an drei konkreten Projekten zeigen, was jedes System tut und warum du alle drei brauchst.
Case 1: Telekommunikation: Warum wechseln Kunden?
Ein Mobilfunkanbieter will verstehen, warum Kunden zur Konkurrenz gehen. 35 Interviews mit ehemaligen Kunden, die gekündigt haben.
Was die Vektordatenbank findet:
Du fragst: "Welche Rolle spielte der Kundenservice beim Wechsel?"
Strg+F nach "Kundenservice" liefert 12 Treffer. Die semantische Suche findet 29; darunter auch "die haben mich ewig in der Warteschleife hängen lassen", "am Telefon konnte mir keiner helfen" und "ich hab dreimal dieselbe Geschichte erzählt". Alles relevant, aber kein einziges Mal taucht das Wort "Kundenservice" auf.
Was der Knowledge Graph ergänzt:
Die Suche findet Aussagen. Aber wer hat sie gemacht? Der Graph weiß: 23 der 39 Aussagen stammen von Kunden, die länger als 5 Jahre dabei waren. Bei Neukunden unter einem Jahr taucht das Thema kaum auf. Der Graph weiß auch: Die meisten, die Serviceprobleme erwähnen, erwähnen im selben Interview auch Preiserhöhungen. Die Themen hängen zusammen.
Was das Sprachmodell daraus macht:
Es bekommt die 29 Aussagen plus die Strukturinfo aus dem Graph. Seine Antwort: "Serviceprobleme werden vor allem von langjährigen Kunden als Wechselgrund genannt (23 von 34 Aussagen). Bei dieser Gruppe treten Serviceprobleme häufig zusammen mit Preiserhöhungen auf, was auf einen Zusammenhang zwischen wahrgenommener Wertschätzung und Preisakzeptanz hindeutet."
Daneben: die Originalzitate, die diese Interpretation stützen.
Case 2: Nachhaltigkeit: Was bedeutet "nachhaltig" für dich?
Ein Konsumgüterhersteller will sein Nachhaltigkeits-Messaging verbessern. 45 Interviews mit Kunden verschiedener Altersgruppen.
Was die Vektordatenbank findet:
Du fragst nach "Nachhaltigkeit". Die Suche findet natürlich alle, die das Wort benutzen. Aber auch: "mir ist wichtig, dass das lange hält", "ich will nicht ständig neu kaufen müssen", "weniger Plastik wäre gut", "die sollen mal an meine Enkel denken". Bedeutungsähnlich, völlig unterschiedliche Wortwahl.
Was der Knowledge Graph ergänzt:
Die Bedeutungen sind ähnlich, aber der Graph zeigt: Es sind verschiedene Themen. "Langlebigkeit" wird von 28 Teilnehmern erwähnt, "Verpackung" von 15, "Umweltauswirkungen" von 22, "Generationengerechtigkeit" von 8. Manche überlappen: 12 Teilnehmer sprechen sowohl über Langlebigkeit als auch über Verpackung. Andere nicht: Generationengerechtigkeit kommt fast nur bei über 50-Jährigen vor.
Was das Sprachmodell daraus macht:
Es erkennt, dass "Nachhaltigkeit" für verschiedene Zielgruppen verschiedene Dinge bedeutet. Die Analyse unterscheidet zwischen pragmatischer Nachhaltigkeit (Langlebigkeit, Reparierbarkeit) und wertebasierter Nachhaltigkeit (Umwelt, Generationen). Mit Quellenangaben, die du prüfen kannst.
Case 3: KI-Akzeptanz: Warum lehnen manche Menschen KI ab?
Ein Unternehmen will KI-Tools einführen und versteht nicht, warum ein Teil der Belegschaft skeptisch ist. 35 Interviews mit Mitarbeitenden verschiedener Abteilungen.
Was die Vektordatenbank findet:
Du fragst nach "Bedenken gegenüber KI". Die Vektorsuche findet die offensichtlichen ("ich trau dem nicht") und die versteckten ("wer kontrolliert das eigentlich?", "was passiert mit meinen Daten?", "das macht meinen Job überflüssig"). Alles Bedenken, keines benutzt das Wort.
Was der Knowledge Graph ergänzt:
Der Graph zeigt Cluster: Datenschutzbedenken kommen aus IT und Legal, Jobangst kommt aus Sachbearbeitung und Kundenservice, Kontrollverlust-Themen kommen quer durch alle Abteilungen. Er zeigt auch Zusammenhänge: Wer Datenschutzbedenken äußert, äußert selten Jobangst, und umgekehrt. Es sind verschiedene Gruppen mit verschiedenen Themen.
Was das Sprachmodell daraus macht:
Es erkennt drei distinkte Skeptiker-Profile mit unterschiedlichen Treibern und kann für jedes konkrete Aussagen und spezifische O-Töne als Beleg liefern. Die Empfehlung: unterschiedliche Kommunikationsstrategien für unterschiedliche Gruppen.
Was ist eigentlich eine Vektordatenbank?
Technisch erklärt:
Eine Vektordatenbank speichert Text nicht als Zeichenketten, sondern als Vektoren – Listen von Zahlen, die die Bedeutung des Textes repräsentieren. Diese Vektoren werden von sogenannten Embedding-Modellen erzeugt, die auf Milliarden von Texten trainiert wurden. Zwei Texte mit ähnlicher Bedeutung haben ähnliche Vektoren, auch wenn sie völlig unterschiedliche Wörter benutzen.
Bekannte Vektordatenbanken sind Qdrant (Open Source, entwickelt von einem Berliner Unternehmen, DSGVO-konform), Pinecone (Cloud-basiert), Weaviate (Open Source), und Milvus (Open Source, spezialisiert auf große Datenmengen). Aber auch klassische lexikalische Suchmaschinen wie Solr oder ElasticSearch haben nachgezogen und semantische Suchen integriert.
Auch wenn du eine Suchanfrage stellst, wird sie ebenfalls in einen Vektor umgewandelt. Die Datenbank vergleicht dann diesen Vektor mit allen gespeicherten Vektoren und liefert die mit der höchsten Ähnlichkeit zurück. Das nennt sich "Approximate Nearest Neighbor Search" und funktioniert auch bei Millionen von Einträgen in Millisekunden.
"Das ist mir zu technisch"
Stell dir vor, jeder Satz bekommt eine Position auf einer riesigen Landkarte der Bedeutungen. Sätze über Frustration landen in der "Frustrations-Gegend", egal ob sie "frustriert", "genervt" oder "zum Verzweifeln" sagen. Wenn du suchst, landest du mit deiner Frage auch irgendwo auf dieser Karte, und das System zeigt dir alles in der Nähe.
Es ist wie Spotify, das dir Songs empfiehlt, die "so ähnlich klingen wie" dein Lieblingslied – nur für Textbedeutung statt für Musik.
Was die Vektordatenbank nicht kann:
Sie findet ähnliche Aussagen, versteht aber keine Beziehungen. Sie weiß nicht, wer den Satz gesagt hat, in welchem Kontext, welche anderen Themen im selben Interview vorkamen. Sie findet Bedeutungsähnlichkeit, aber keine Struktur.
Und was genau ist ein Knowledge Graph?
Technisch erklärt:
Ein Knowledge Graph speichert sogenannte Entitäten (Teilnehmer, Interviews, Themen, Aussagen) und die Beziehungen zwischen ihnen. Die Datenstruktur besteht aus Knoten (Nodes) und Kanten (Edges). Ein Knoten könnte "Teilnehmerin Anna" sein, ein anderer "Thema Datenschutz", und die Kante dazwischen sagt "hat erwähnt".
Die bekannteste Graph-Datenbank ist Neo4j (kommerziell und Open Source Community Edition), die eine eigene Abfragesprache namens Cypher verwendet. Andere Optionen sind Amazon Neptune, ArangoDB oder FalkorDB.
Du kannst Fragen stellen wie "Welche Teilnehmer haben sowohl Thema A als auch Thema B erwähnt?" oder "Welche Themen treten häufig gemeinsam auf?" oder "Wie viele Teilnehmer aus Abteilung X haben Thema Y erwähnt?". Das sind Strukturfragen, keine Textfragen.
Ein Vergleich
Stell dir ein Netz aus Beziehungen vor, wie bei einer Krimiserie an der Wand. Fotos von Personen, Orten, Ereignissen, verbunden mit roten Fäden, die man stunden-, tage-, wochenlang, die ganze Staffel lang anstarrt. Der Graph ist diese Wand, nur digital und durchsuchbar. Du kannst fragen: "Wer war am Tatort UND kannte das Opfer UND hat ein Motiv?" Der Graph findet die Verbindungen.
Es ist wie LinkedIn, das dir zeigt, über wie viele Ecken du jemanden kennst – nur für Forschungsdaten statt für Kontakte.
Die Grenzen eines Knowledge Graph
Er findet keine ähnlichen Aussagen, wenn sie unterschiedliche Worte benutzen. Er kennt nur, was explizit eingetragen wurde. "Frustration" und "genervt" sind für ihn zwei verschiedene Wörter ohne Verbindung, es sei denn, jemand hat sie verknüpft oder das System hat sie automatisch demselben Thema zugeordnet. Deshalb ist die Kombination mit einer semantischen Suche so stark.
Warum man beides braucht
Die Vektordatenbank findet, was bedeutungsähnlich ist, auch über Wortwahl-Grenzen hinweg. Aber sie weiß nicht, wer es gesagt hat oder wie Themen zusammenhängen.
Der Knowledge Graph kennt alle Beziehungen und Strukturen. Aber er findet keine Aussagen, die andere Worte benutzen.
| Fähigkeit | Vektordatenbank | Knowledge Graph |
|---|---|---|
| Findet "genervt" wenn du "frustriert" suchst | ✓ | ✗ |
| Weiß, wer die Aussage gemacht hat | ✗ | ✓ |
| Findet Themen-Cluster | ✗ | ✓ |
| Versteht synonyme Formulierungen | ✓ | ✗ |
| Zeigt Beziehungen zwischen Themen | ✗ | ✓ |
| Funktioniert ohne vordefinierte Kategorien | ✓ | ✗ |
Erst zusammen ergibt das ein System, das sowohl bedeutungsähnliche Aussagen findet als auch weiß, wer sie gemacht hat und welche Themen zusammenhängen. Die Vektordatenbank liefert die relevanten Fundstellen. Der Graph liefert den Kontext.
Das Sprachmodell bekommt dann beides: relevante Aussagen und Strukturinformation. Seine Aufgabe ist Interpretation – aber nur auf Basis dessen, was ihm geliefert wird. Es kann nichts erfinden, weil es keinen Zugriff auf Erfundenes hat.
Was du davon hast
Du findest, was du suchst. Auch wenn die Teilnehmer andere Worte benutzt haben. Auch in 100 Interviews.
Du verstehst die Struktur. Nicht nur "das Thema kommt vor", sondern: wie oft, bei wem, in welchem Zusammenhang mit anderen Themen.
Du kannst nachvollziehen. Jede Aussage des Systems verweist auf Originalzitate. Du musst nicht glauben, du kannst prüfen. Das ist entscheidend, wenn du Ergebnisse vor Stakeholdern vertreten musst.
Du sparst Zeit. Die Architektur erledigt in Minuten, was manuell Tage dauern würde: alle Interviews nach einem Thema durchsuchen, Muster über Teilnehmergruppen erkennen, Zusammenhänge zwischen Themen finden.
Grenzen
Semantische Ähnlichkeit ist nicht immer, was du brauchst. Manchmal suchst du Widersprüche, Ausnahmen, das eine Interview, das gegen das Muster läuft. Dafür musst du anders fragen. Und dafür haben wir unsere smarte, hybride, KI-gestützte Suche entwickelt.
Der Knowledge Graph ist nur so gut wie die automatische Themenextraktion. Wenn sie ein Thema übersieht, fehlt es im Graph. Wir verbessern das für dich kontinuierlich; Perfektion gibt es nicht.
Und das Sprachmodell bleibt ein Sprachmodell. Subtile Ironie, kultureller Kontext, das Unausgesprochene: all das kann es übersehen. Die finale Interpretation bleibt bei dir, wo sie hingehört. Wir haben dir dafür den Analysechat entwickelt, dem du deine relevanten Fragen stellen kannst, um in den Deepdive zu gehen, den dein Research benötigt.
Häufig gestellte Fragen
Was unterscheidet diese Architektur von ChatGPT mit Dokumenten-Upload?
ChatGPT mit Dokumenten-Upload verwendet nur ein System: das Sprachmodell selbst. Es hat kein separates Wissen darüber, wer was gesagt hat oder wie Themen zusammenhängen. Bei großen Datenmengen (also bereits mehr als fünf Interviews) beginnt es, Informationen zu vermischen oder zu erfinden. Unsere Architektur trennt Suche (Vektordatenbank), Struktur (Graph) und Interpretation (LLM), wodurch jede Komponente ihre Stärke einbringen kann.
Brauche ich technisches Wissen, um das System zu nutzen?
Nein. Die technische Architektur läuft im Hintergrund. Du interagierst mit dem QUALLEE Chat-Interface, stellst Fragen in natürlicher Sprache und bekommst relevante, faktenbasierte Antworten. Du musst weder wissen, was ein Vektor ist, noch wie man Cypher-Abfragen schreibt.
Wie viele Interviews kann das System verarbeiten?
Die Architektur skaliert theoretisch unbegrenzt. In der Praxis haben wir mit bis zu 150 Interviews pro Projekt gearbeitet. Der limitierende Faktor ist nicht die Technik, sondern die Qualität der automatischen Themenextraktion, die bei sehr großen Mengen manuell geprüft werden sollte.
Kann ich bei QUALLEE eigene Transkripte hochladen?
Ja, du kannst Transkripte hochladen und analysieren. Unser System segmentiert sie automatisch, erzeugt Embeddings und baut den Knowledge Graph auf. Alternativ kannst du zusätzlich die KI-Interviews von QUALLEE nutzen, bei denen Transkription und Strukturierung automatisch erfolgen. Schöner Nebeneffekt: So validierst du die Qualität der Ergebnisse. Wir versprechen dir: Schon nach fünf Interviews wirst du überrascht sein.
Wie unterscheidet sich das von klassischer QDA-Software wie MAXQDA oder Atlas.ti?
Klassische QDA-Software basiert auf manuellem Coding: Du liest jeden Text und weist Codes zu. Das ist präzise, aber zeitaufwendig. QUALLEE automatisiert die Themenextraktion und ermöglicht semantische Suche über alle Interviews hinweg. Du kannst Fragen stellen, statt Codes zu vergeben. Beide Ansätze haben ihre Berechtigung; QUALLEE ist besonders dann sinnvoll, wenn du viele Interviews hast und schnell Muster erkennen willst.
Werden meine Daten für KI-Training verwendet?
Nein. Deine Interviewdaten werden ausschließlich für deine Analyse verwendet. Sie fließen nicht in das Training von Sprachmodellen ein. Die Vektordatenbank und der Knowledge Graph existieren nur für dein Projekt und werden auf Wunsch vollständig gelöscht. Und alle Daten werden automatisch verschlüsselt.
Wo speichert ihr meine Daten in eurer Vektor- und Graph-Datenbank?
Wir verwenden ausschließlich Open Source Software und Komponenten, die wir auf unseren eigenen Servern in Deutschland betreiben.
Selbst ausprobieren
Du willst sehen, wie sich das anfühlt? Starte ein Testprojekt, lade eigene Transkripte hoch oder lass die KI Interviews führen. Danach kannst du den Analysechat testen. Du wirst merken, wie es ist, wenn Antworten auf konkrete Quellen verweisen, die du prüfen kannst.
Wie gesagt, ein solches System ist ein lebendiges System, das wir permanent anpassen und optimieren. Gib uns dein Feedback und hilf uns damit, es immer besser zu machen als es ohnehin schon ist.

