
Privacy by Design significa integrar la protección de datos en la arquitectura del software desde el principio, no añadirla después. En QUALLEE, esto incluye: gestión granular del consentimiento con registro de auditoría, eliminación automática de datos según períodos de retención definidos, autoservicio para los derechos de los interesados y total transparencia en el procesamiento con IA. Este artículo muestra la implementación técnica concreta.
Por qué la protección de datos es arquitectura
La mayoría de los productos de software tratan la protección de datos como una lista de verificación que marcar antes del lanzamiento. Un banner de cookies aquí, una política de privacidad allá, quizás una ventana de consentimiento. Listo.
Hasta que alguien pregunta dónde exactamente se almacena el consentimiento. Hasta que un usuario quiere exportar sus datos. Hasta que el regulador quiere saber cuánto tiempo se conservan qué datos y por qué.
Añadir la protección de datos después es más caro que integrarla desde el principio. Ese fue el razonamiento cuando construimos QUALLEE. Privacy by Design no es filosofía; es una decisión arquitectónica que se toma al principio o se paga por corregir después.
Los siete principios de Ann Cavoukian
La Dra. Ann Cavoukian formuló Privacy by Design en los años 90. Siete principios que fueron reconocidos como estándar por las autoridades internacionales de protección de datos en 2010. El RGPD los adoptó en el artículo 25.
Los principios suenan abstractos: "Proactivo, no reactivo", "Privacidad por defecto", "Seguridad de extremo a extremo". En la práctica, significan decisiones concretas.
Proactivo, no reactivo significa: Antes de construir una funcionalidad, nos preguntamos qué datos necesita y por cuánto tiempo. No cuando alguien pregunta sobre los períodos de retención.
Privacidad por defecto significa: Si un usuario no hace nada, sus datos siguen protegidos. Sin trampas de opt-out, sin casillas de marketing premarcadas.
Privacidad integrada en el diseño significa: La protección de datos no es un componente que se activa o desactiva. Está en el esquema de base de datos, en los endpoints de la API, en los componentes de la UI.
Productos de IA y el problema de confianza
Los productos de IA tienen un problema de imagen en cuanto a protección de datos. Los titulares sobre datos de entrenamiento, sobre modelos que reproducen información personal, sobre flujos de datos opacos han dejado huella.
El problema es real, pero no inevitable. Los productos impulsados por IA pueden ser conformes; solo requieren más cuidado en la arquitectura.
En QUALLEE, los datos de entrevistas fluyen a través de modelos de IA de Anthropic y OpenAI. Ese es el núcleo del producto. Al mismo tiempo, hemos trazado límites claros.
Los datos brutos permanecen en nuestros servidores en Alemania. Solo el contenido de texto necesario para el análisis va a las APIs de IA, transmitido de forma cifrada. Ambos proveedores han firmado Acuerdos de Procesamiento de Datos que excluyen el uso para entrenamiento de modelos. Hemos documentado y archivado los DPAs de OpenAI, Anthropic, Hetzner, Stripe y Resend.
La IA analiza lo que la gente dice; no analiza cómo se ven. Sin reconocimiento facial, sin detección de emociones a partir de video o audio. Esto está prohibido en ciertos contextos desde febrero de 2025 por el EU AI Act, pero lo construimos así desde el principio.
Gestión del consentimiento según el artículo 6 del RGPD
El RGPD distingue diferentes bases legales para el procesamiento de datos. El artículo 6 las enumera. Dos son particularmente relevantes para nosotros: ejecución del contrato y consentimiento.
Cuando un cliente de pago usa el chat de análisis, procesamos sus datos sobre la base de la ejecución del contrato. Se ha suscrito, el análisis es parte del contrato. Un aviso de que se usa IA es suficiente. Sin modal, sin casilla, sin almacenamiento.
Es diferente cuando entran en juego datos de terceros. Cuando un investigador sube transcripciones que contienen declaraciones de participantes en entrevistas. O cuando alguien importa preguntas clave que pueden contener información personal. Aquí necesitamos consentimiento explícito, y debemos almacenarlo.
La distinción suena académica pero tiene consecuencias prácticas. Un aviso informativo es una frase de texto en la UI. Un consentimiento almacenado es una entrada de base de datos con marca de tiempo, dirección IP, user agent y número de versión del texto de consentimiento.
| Ubicación | Qué se requiere | Justificación |
|---|---|---|
| Chat de análisis | Aviso informativo | El usuario es parte del contrato |
| Chat de soporte | Aviso informativo | Ejecución del contrato |
| Importación de preguntas | Consentimiento + almacenamiento | Datos de terceros posibles |
| Carga de transcripciones | Consentimiento + almacenamiento | Datos de terceros (participantes) |
| Participación en entrevista | Consentimiento + almacenamiento | El participante no es parte del contrato |
Implementación técnica de la gestión del consentimiento
La gestión del consentimiento necesita infraestructura. Para nosotros, son dos tablas de base de datos, varios endpoints de API y un hook de React.
La tabla UserAiConsent almacena los consentimientos de usuarios registrados. Cada entrada contiene el tipo de consentimiento, el momento de la concesión, opcionalmente el momento de la revocación, dirección IP, user agent y la versión del texto de consentimiento. La combinación de ID de usuario y tipo de consentimiento es única; un usuario solo puede tener un consentimiento activo por tipo.
La tabla IntervieweeConsent es para participantes de entrevistas. No son usuarios registrados, así que no tienen ID de usuario. En su lugar, vinculamos el consentimiento al ID de sesión. Además, almacenamos un hash SHA-256 del texto de consentimiento mostrado. Esto nos permite probar después exactamente qué texto vio el participante.
El hook React useAiConsent hace que la gestión del consentimiento sea utilizable en el frontend. Verifica al cargar el componente si ya existe un consentimiento. Si no, muestra un modal. Después de la confirmación, guarda el consentimiento a través de la API y recuerda el estado para la sesión.
const { hasConsent, grantConsent, showConsentModal } = useAiConsent("import_questions")
// Antes de una acción que requiere consentimiento:
if (!hasConsent) {
setShowConsentModal(true)
return
}
// Consentimiento existente, proceder con la acción
Para la revocación, no eliminamos la entrada de consentimiento sino que establecemos una fecha revokedAt. El RGPD permite conservar los registros de consentimiento incluso después de la revocación; son parte de la obligación de documentación.
Transparencia de IA según el EU AI Act
El EU AI Act requiere desde agosto de 2025 que los usuarios sean informados cuando interactúan con un sistema de IA. Lo construimos así desde el principio.
El ConsentDialog para participantes de entrevistas deja inequívocamente claro que un sistema de IA conduce la entrevista. El texto está disponible en cinco idiomas: alemán, inglés, francés, español, italiano. Sin traducción automática, sino textos localizados.
El diálogo contiene tres piezas de información centrales: Los datos se almacenan cifrados en un servidor alemán. El procesamiento lo realizan modelos de IA. Los datos no se usan para entrenamiento de IA.
Además de la casilla de consentimiento, hay una verificación de captcha. Esto no es un requisito del RGPD sino protección contra accesos automatizados.
En el panel de control, los avisos de IA son menos prominentes pero están presentes. Un pequeño texto sobre el chat: "Análisis impulsado por IA". Sin modal, sin popup; el usuario sabe sin ser interrumpido.
Eliminación automática de datos por período de retención
Establecer períodos de retención es fácil. Cumplirlos es más difícil.
El RGPD requiere en el artículo 5 que los datos no se conserven más tiempo del necesario. Suena obvio pero falla regularmente en la práctica. El estudio terminó, los datos siguen en algún lugar, nadie se ocupa de ellos.
Hemos configurado un cronjob que se ejecuta diariamente a las 02:30. Verifica tres categorías: Los tickets de soporte de más de 24 meses se eliminan. Las sesiones de entrevista archivadas de más de 12 meses se eliminan. Los registros de consentimiento de usuarios eliminados se retiran después de 36 meses.
El job se ejecuta en modo dry-run cuando se inicia manualmente. Muestra qué se eliminaría sin eliminar realmente. Solo con la bandera --execute se eliminan realmente los datos.
| Tipo de datos | Período de retención | Eliminación automática |
|---|---|---|
| Tickets de soporte | 24 meses | Sí |
| Sesiones archivadas | 12 meses | Sí |
| Registros de consentimiento | 36 meses después de eliminación | Sí |
| Datos de proyecto | Duración del proyecto + 12 meses | Al eliminar el proyecto |
Derechos de los interesados como autoservicio
El RGPD da a las personas derechos sobre sus datos: Acceso (Art. 15), Rectificación (Art. 16), Supresión (Art. 17), Portabilidad (Art. 20). En muchos productos, estos son procesos manuales: El usuario escribe un email, alguien exporta manualmente los datos, los envía como archivo ZIP.
Para nosotros, son funcionalidades en la configuración de la cuenta.
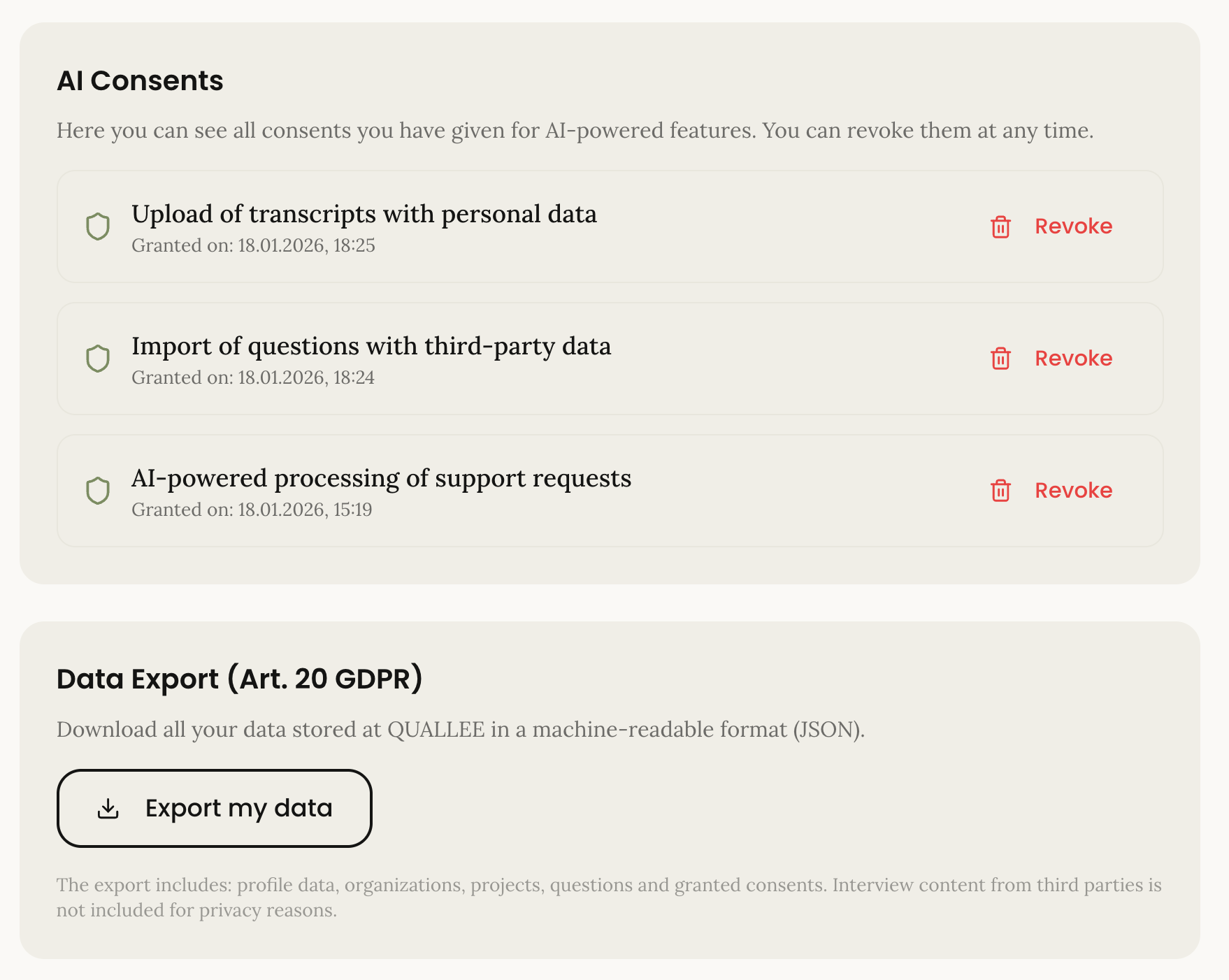
La página de privacidad muestra todos los consentimientos otorgados. Los usuarios pueden revocarlos individualmente. La revocación es tan fácil como el otorgamiento; eso es lo que el artículo 7(3) del RGPD requiere.
La exportación de datos genera un archivo JSON con todos los datos personales: Información de cuenta, proyectos, consentimientos otorgados. Legible por máquina, como requiere el artículo 20.
La eliminación de cuenta es una eliminación suave con anonimización. Eliminamos los datos personales pero conservamos los datos de proyecto anonimizados si son relevantes para otros miembros del equipo. Los registros de consentimiento se conservan; el artículo 17(3) lo permite explícitamente.
Lo que aprendimos de esto
Privacy by Design lleva tiempo. Construir la infraestructura de consentimiento llevó más tiempo que un simple banner de cookies. La eliminación automática requiere más planificación que "eliminaremos cuando alguien se queje".
Esta inversión vale la pena, no principalmente por las multas evitadas (aunque las sanciones del RGPD superaron los 2 mil millones de euros en 2025), sino por la confianza. Los investigadores trabajan con datos sensibles. Quieren saber que sus participantes están protegidos. Un concepto de protección de datos trazable es un argumento de venta.
El EU AI Act elevó los requisitos, no los cambió. Quienes construyen sus productos de IA de forma transparente y con economía de datos desde el principio no tendrán que apresurarse en agosto de 2026.
Preguntas frecuentes
¿Qué es Privacy by Design?
Privacy by Design es un concepto de la Dra. Ann Cavoukian que pide integrar la protección de datos en el desarrollo de sistemas desde el principio, en lugar de añadirla después. El RGPD lo consagró en el artículo 25 como "protección de datos desde el diseño y por defecto".
¿Cómo se diferencia un aviso informativo del consentimiento explícito?
Un aviso informativo es suficiente para la ejecución del contrato (Art. 6(1)(b) RGPD) cuando el usuario mismo es parte del contrato. El consentimiento explícito con almacenamiento se requiere cuando se procesan datos de terceros o el interesado no es parte del contrato.
¿Cuánto tiempo deben conservarse los registros de consentimiento?
El RGPD no especifica un período concreto, pero las empresas deben poder probar que se dio el consentimiento. Se recomiendan 3 años después de la revocación o fin del contrato, coincidiendo con el plazo de prescripción civil.
¿Se usan mis datos para entrenar la IA?
No. Tanto OpenAI como Anthropic han firmado Acuerdos de Procesamiento de Datos que excluyen el uso de datos de API para entrenamiento de modelos. Los datos brutos permanecen en servidores alemanes.
Pruébalo tú mismo
QUALLEE realiza entrevistas impulsadas por IA que son conformes desde el principio. Servidores alemanes, DPAs documentados, períodos de retención automáticos, procesos de consentimiento transparentes. Una entrevista dura aproximadamente 20 a 30 minutos.