
QUALLEE combines three specialized technologies for analyzing large interview volumes: a vector database for semantic search, a knowledge graph for relationships and structures, and a language model that only analyzes based on anchored data. This disruptive architecture makes it possible to analyze 20, 50, or 100 interviews just as precisely as 5 – without hallucinations, without lost context, with traceable source references. Here we explain how it works, without getting too technical and abstract.
The statement exists, you're sure of it. You heard it when you conducted the interview. Something about the moment when the participant almost quit. Now, three weeks later, facing 400 pages of transcript: no chance. Ctrl+F doesn't help because you can't remember the exact word. Was it "trust"? "Skepticism"? "Uncertain"? She probably phrased it completely differently.
That was our starting problem. Not just "how do we make qualitative research faster," but: How do you find what you're looking for in a mountain of transcripts without knowing the exact words? And how do you ensure that the AI helping you doesn't start making things up?
Why a Single AI Model Isn't Enough
The obvious solution would be to give everything to a language model like OpenAI's GPT or Anthropic's Claude and ask questions. They start hallucinating after just two or three interviews. At eight or twelve, it falls apart.
Language models have a context window: the maximum amount of text they can process simultaneously. A one-hour interview, when transcribed, yields about 8,000 to 10,000 words. With 40 interviews, you're at 400,000 words. Even the largest models with 200,000-token context windows can't handle that, and when they try, something dangerous happens: They completely omit important things, they start inventing things. They confuse participants and see patterns that don't exist. And the worst part: It all sounds plausible, coherent, and precisely analyzed.
Instead of throwing everything at the AI, you could have it summarize the transcripts beforehand, or do it yourself. But a summary is already an interpretation. You lose the verbatim quotes, the nuances, the context. But that's exactly what makes qualitative research valuable and relevant.
The Three Systems and Their Tasks
We built an architecture with three specialized technologies. Each solves a different problem. And together they create something none could do alone.
Vector Database
Semantic Search
Finds meanings, not just words. Recognizes synonyms like "frustrated" and "annoyed."
Knowledge Graph
Relationships & Structures
Connects Who with What and How. Reveals connections between topics and speakers.
Grounded LLM
Analysis & Interpretation
Analyzes only based on verified data. Prevents hallucinations.
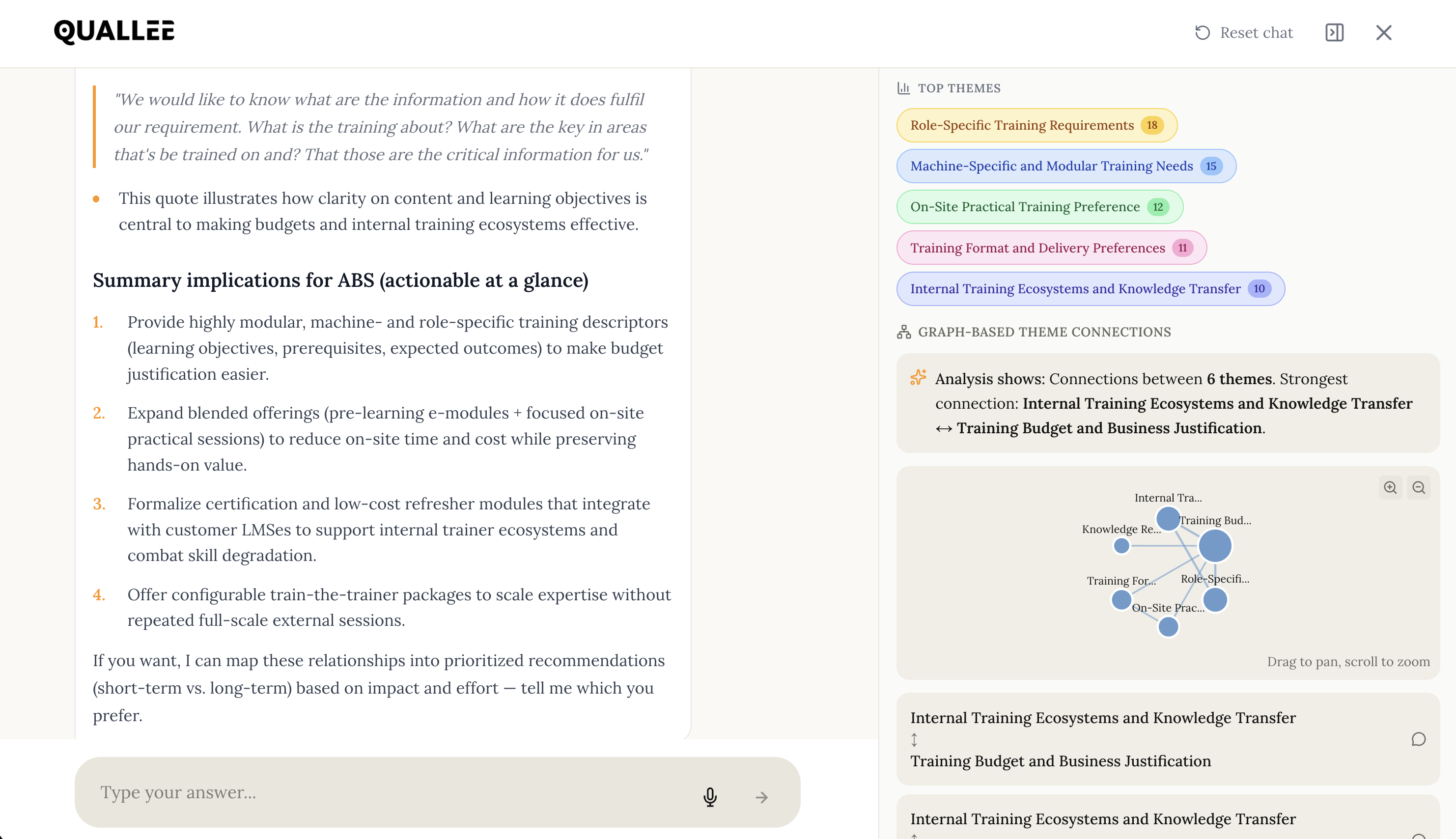
The Synergy in Analysis Chat: Precision at Any Scale
Analyze 20, 50, or 100 interviews with the same accuracy as five.
GDPR-compliantSystem 1: Vector Database – finds statements by meaning, not by words.
System 2: Knowledge Graph – stores who said what and how topics connect.
System 3: LLM with Anchoring – analyzes and interprets, but only based on what the other two provide.
That sounds abstract. Let me show you through three concrete projects what each system does and why you need all three.
Case 1: Telecommunications: Why Do Customers Switch?
A mobile provider wants to understand why customers leave for competitors. 35 interviews with former customers who canceled.
What the vector database finds:
You ask: "What role did customer service play in the switch?"
Ctrl+F for "customer service" yields 12 hits. The semantic search finds 29, including "they kept me on hold forever," "nobody on the phone could help me," and "I told the same story three times." All relevant, but not once does the word "customer service" appear.
What the knowledge graph adds:
The search finds statements. But who made them? The graph knows: 23 of the 39 statements come from customers who had been with the company for more than 5 years. With new customers under one year, the topic barely comes up. The graph also knows: Most people who mention service problems also mention price increases in the same interview. The topics are connected.
What the language model makes of it:
It receives the 29 statements plus the structural info from the graph. Its answer: "Service problems are mainly cited as a reason for switching by long-term customers (23 of 34 statements). In this group, service problems frequently occur together with price increases, suggesting a connection between perceived appreciation and price acceptance."
Alongside: the original quotes supporting this interpretation.
Case 2: Sustainability: What Does "Sustainable" Mean to You?
A consumer goods manufacturer wants to improve its sustainability messaging. 45 interviews with customers of various age groups.
What the vector database finds:
You ask about "sustainability." The search naturally finds everyone who uses the word. But also: "it's important to me that it lasts long," "I don't want to keep buying new things," "less plastic would be good," "they should think about my grandchildren." Similar in meaning, completely different wording.
What the knowledge graph adds:
The meanings are similar, but the graph shows: These are different topics. "Durability" is mentioned by 28 participants, "packaging" by 15, "environmental impact" by 22, "intergenerational fairness" by 8. Some overlap: 12 participants discuss both durability and packaging. Others don't: Intergenerational fairness appears almost exclusively among those over 50.
What the language model makes of it:
It recognizes that "sustainability" means different things to different target groups. The analysis distinguishes between pragmatic sustainability (durability, repairability) and values-based sustainability (environment, generations). With source references you can verify.
Case 3: AI Acceptance: Why Do Some People Reject AI?
A company wants to introduce AI tools and doesn't understand why some of the workforce is skeptical. 35 interviews with employees from various departments.
What the vector database finds:
You ask about "concerns about AI." The vector search finds the obvious ones ("I don't trust it") and the hidden ones ("who's actually controlling this?", "what happens to my data?", "this will make my job obsolete"). All concerns, none using the word.
What the knowledge graph adds:
The graph shows clusters: Privacy concerns come from IT and Legal, job fears come from administrative and customer service, control loss themes come across all departments. It also shows connections: Those who express privacy concerns rarely express job fears, and vice versa. They're different groups with different issues.
What the language model makes of it:
It identifies three distinct skeptic profiles with different drivers and can provide concrete statements and specific quotes as evidence for each. The recommendation: different communication strategies for different groups.
What Exactly Is a Vector Database?
Technical explanation:
A vector database stores text not as character strings, but as vectors – lists of numbers representing the text's meaning. These vectors are generated by so-called embedding models trained on billions of texts. Two texts with similar meaning have similar vectors, even when they use completely different words.
Well-known vector databases include Qdrant (open source, developed by a Berlin company, GDPR-compliant), Pinecone (cloud-based), Weaviate (open source), and Milvus (open source, specialized for large data volumes). But even classic lexical search engines like Solr or ElasticSearch have caught up and integrated semantic search.
When you make a search query, it's also converted into a vector. The database then compares this vector with all stored vectors and returns those with the highest similarity. This is called "Approximate Nearest Neighbor Search" and works in milliseconds even with millions of entries.
"That's too technical for me"
Imagine every sentence gets a position on a huge map of meanings. Sentences about frustration land in the "frustration area," whether they say "frustrated," "annoyed," or "at my wit's end." When you search, your question also lands somewhere on this map, and the system shows you everything nearby.
It's like Spotify recommending songs that "sound similar to" your favorite song – only for text meaning instead of music.
What the vector database can't do:
It finds similar statements but doesn't understand relationships. It doesn't know who said the sentence, in what context, what other topics came up in the same interview. It finds semantic similarity, but no structure.
And What Exactly Is a Knowledge Graph?
Technical explanation:
A knowledge graph stores so-called entities (participants, interviews, topics, statements) and the relationships between them. The data structure consists of nodes and edges. A node could be "Participant Anna," another "Topic Data Privacy," and the edge between them says "mentioned."
The best-known graph database is Neo4j (commercial and open source Community Edition), which uses its own query language called Cypher. Other options include Amazon Neptune, ArangoDB, or FalkorDB.
You can ask questions like "Which participants mentioned both Topic A and Topic B?" or "Which topics frequently occur together?" or "How many participants from Department X mentioned Topic Y?" These are structural questions, not text questions.
A comparison
Imagine a web of relationships, like in a crime series on the wall. Photos of people, places, events, connected by red threads that you stare at for hours, days, weeks, the whole season. The graph is this wall, just digital and searchable. You can ask: "Who was at the crime scene AND knew the victim AND has a motive?" The graph finds the connections.
It's like LinkedIn showing you how many degrees away you know someone – only for research data instead of contacts.
The Limits of a Knowledge Graph
It can't find similar statements when they use different words. It only knows what was explicitly entered. "Frustration" and "annoyed" are two different words with no connection to it, unless someone linked them or the system automatically assigned them to the same topic. That's why the combination with semantic search is so powerful.
Why You Need Both
The vector database finds what's semantically similar, even across word choice boundaries. But it doesn't know who said it or how topics connect.
The knowledge graph knows all relationships and structures. But it can't find statements that use different words.
| Capability | Vector Database | Knowledge Graph |
|---|---|---|
| Finds "annoyed" when you search "frustrated" | ✓ | ✗ |
| Knows who made the statement | ✗ | ✓ |
| Finds topic clusters | ✗ | ✓ |
| Understands synonymous phrasings | ✓ | ✗ |
| Shows relationships between topics | ✗ | ✓ |
| Works without predefined categories | ✓ | ✗ |
Only together do they create a system that both finds semantically similar statements and knows who made them and how topics connect. The vector database provides the relevant findings. The graph provides the context.
The language model then receives both: relevant statements and structural information. Its task is interpretation – but only based on what it's given. It can't invent anything because it has no access to invented material.
What You Get From This
You find what you're looking for. Even when participants used different words. Even in 100 interviews.
You understand the structure. Not just "the topic appears," but: how often, with whom, in what connection with other topics.
You can verify. Every statement from the system references original quotes. You don't have to believe, you can check. This is crucial when you need to defend results to stakeholders.
You save time. The architecture does in minutes what would take days manually: search all interviews for a topic, recognize patterns across participant groups, find connections between topics.
Limitations
Semantic similarity isn't always what you need. Sometimes you're looking for contradictions, exceptions, the one interview that goes against the pattern. For that, you need to ask differently. And for that, we developed our smart, hybrid, AI-powered search.
The knowledge graph is only as good as the automatic topic extraction. If it misses a topic, it's missing from the graph. We continuously improve this for you; perfection doesn't exist.
And the language model remains a language model. Subtle irony, cultural context, the unspoken: it can all be missed. The final interpretation stays with you, where it belongs. We developed the analysis chat for you, where you can ask your relevant questions to go into the deep dive your research needs.
Frequently Asked Questions
What distinguishes this architecture from ChatGPT with document upload?
ChatGPT with document upload uses only one system: the language model itself. It has no separate knowledge about who said what or how topics connect. With large data volumes (meaning more than five interviews), it starts mixing up or inventing information. Our architecture separates search (vector database), structure (graph), and interpretation (LLM), allowing each component to contribute its strength.
Do I need technical knowledge to use the system?
No. The technical architecture runs in the background. You interact with the QUALLEE chat interface, ask questions in natural language, and get relevant, fact-based answers. You don't need to know what a vector is or how to write Cypher queries.
How many interviews can the system process?
The architecture theoretically scales indefinitely. In practice, we've worked with up to 150 interviews per project. The limiting factor isn't the technology, but the quality of automatic topic extraction, which should be manually reviewed for very large volumes.
Can I upload my own transcripts to QUALLEE?
Yes, you can upload and analyze transcripts. Our system automatically segments them, generates embeddings, and builds the knowledge graph. Alternatively, you can also use QUALLEE's AI interviews, where transcription and structuring happen automatically. Nice side effect: This validates the quality of the results. We promise you: After just five interviews, you'll be surprised.
How does this differ from traditional QDA software like MAXQDA or Atlas.ti?
Traditional QDA software is based on manual coding: You read every text and assign codes. That's precise but time-consuming. QUALLEE automates topic extraction and enables semantic search across all interviews. You can ask questions instead of assigning codes. Both approaches have their place; QUALLEE is especially useful when you have many interviews and want to quickly recognize patterns.
Is my data used for AI training?
No. Your interview data is used exclusively for your analysis. It doesn't flow into language model training. The vector database and knowledge graph exist only for your project and are completely deleted upon request. And all data is automatically encrypted.
Where do you store my data in your vector and graph database?
We exclusively use open source software and components that we operate on our own servers in Germany.
Try It Yourself
Want to see how it feels? Start a test project, upload your own transcripts, or let the AI conduct interviews. Then you can test the analysis chat. You'll notice what it's like when answers reference concrete sources you can verify.
As mentioned, such a system is a living system that we constantly adjust and optimize. Give us your feedback and help us make it even better than it already is.

