
Privacy by Design significa integrare la protezione dei dati nell'architettura software fin dall'inizio, non aggiungerla in seguito. In QUALLEE, questo include: gestione granulare del consenso con audit trail, cancellazione automatica dei dati secondo periodi di conservazione definiti, self-service per i diritti degli interessati e piena trasparenza nell'elaborazione IA. Questo articolo mostra l'implementazione tecnica concreta.
Perché la protezione dei dati è architettura
La maggior parte dei prodotti software tratta la protezione dei dati come una checklist da spuntare prima del lancio. Un banner dei cookie qui, una privacy policy lì, magari un popup di consenso. Fatto.
Fino a quando qualcuno chiede dove esattamente è memorizzato il consenso. Fino a quando un utente vuole esportare i propri dati. Fino a quando il regolatore vuole sapere per quanto tempo vengono conservati quali dati e perché.
Aggiungere la protezione dei dati in seguito costa di più che integrarla dall'inizio. Questo era il ragionamento quando abbiamo costruito QUALLEE. Privacy by Design non è filosofia; è una decisione architetturale che si prende all'inizio o si paga per correggere dopo.
I sette principi di Ann Cavoukian
La Dott.ssa Ann Cavoukian ha formulato Privacy by Design negli anni '90. Sette principi riconosciuti come standard dalle autorità internazionali per la protezione dei dati nel 2010. Il GDPR li ha adottati nell'articolo 25.
I principi suonano astratti: "Proattivo, non reattivo", "Privacy come impostazione predefinita", "Sicurezza end-to-end". In pratica, significano decisioni concrete.
Proattivo, non reattivo significa: Prima di costruire una funzionalità, ci chiediamo quali dati servono e per quanto tempo. Non quando qualcuno chiede dei periodi di conservazione.
Privacy come impostazione predefinita significa: Se un utente non fa nulla, i suoi dati sono comunque protetti. Nessuna trappola di opt-out, nessuna casella di marketing preselezionata.
Privacy integrata nel design significa: La protezione dei dati non è un componente che si attiva o disattiva. È nello schema del database, negli endpoint API, nei componenti UI.
Prodotti IA e il problema della fiducia
I prodotti IA hanno un problema di immagine riguardo alla protezione dei dati. I titoli sui dati di addestramento, sui modelli che riproducono informazioni personali, sui flussi di dati opachi hanno lasciato il segno.
Il problema è reale, ma non inevitabile. I prodotti alimentati dall'IA possono essere conformi; richiedono solo più cura nell'architettura.
In QUALLEE, i dati delle interviste passano attraverso modelli IA di Anthropic e OpenAI. Questo è il cuore del prodotto. Allo stesso tempo, abbiamo tracciato confini chiari.
I dati grezzi rimangono sui nostri server in Germania. Solo il contenuto testuale necessario per l'analisi va alle API IA, trasmesso in modo crittografato. Entrambi i fornitori hanno firmato Accordi per il Trattamento dei Dati che escludono l'uso per l'addestramento dei modelli. Abbiamo documentato e archiviato i DPA di OpenAI, Anthropic, Hetzner, Stripe e Resend.
L'IA analizza ciò che le persone dicono; non analizza come appaiono. Nessun riconoscimento facciale, nessun rilevamento delle emozioni da video o audio. Questo è vietato in certi contesti dal febbraio 2025 dall'EU AI Act, ma l'abbiamo costruito così fin dall'inizio.
Gestione del consenso secondo l'articolo 6 del GDPR
Il GDPR distingue diverse basi giuridiche per il trattamento dei dati. L'articolo 6 le elenca. Due sono particolarmente rilevanti per noi: esecuzione del contratto e consenso.
Quando un cliente pagante usa la chat di analisi, trattiamo i suoi dati sulla base dell'esecuzione del contratto. Si è abbonato, l'analisi fa parte del contratto. È sufficiente un avviso che indica l'uso dell'IA. Nessun modale, nessuna casella, nessuna memorizzazione.
È diverso quando entrano in gioco dati di terzi. Quando un ricercatore carica trascrizioni contenenti dichiarazioni di partecipanti alle interviste. O quando qualcuno importa domande chiave che potrebbero contenere informazioni personali. Qui abbiamo bisogno del consenso esplicito, e dobbiamo memorizzarlo.
La distinzione sembra accademica ma ha conseguenze pratiche. Un avviso informativo è una frase di testo nell'UI. Un consenso memorizzato è una voce nel database con timestamp, indirizzo IP, user agent e numero di versione del testo di consenso.
| Posizione | Cosa è richiesto | Motivazione |
|---|---|---|
| Chat di analisi | Avviso informativo | L'utente è parte del contratto |
| Chat di supporto | Avviso informativo | Esecuzione del contratto |
| Importazione domande | Consenso + memorizzazione | Possibili dati di terzi |
| Caricamento trascrizioni | Consenso + memorizzazione | Dati di terzi (partecipanti) |
| Partecipazione all'intervista | Consenso + memorizzazione | Il partecipante non è parte del contratto |
Implementazione tecnica della gestione del consenso
La gestione del consenso richiede infrastruttura. Per noi, sono due tabelle di database, diversi endpoint API e un hook React.
La tabella UserAiConsent memorizza i consensi degli utenti registrati. Ogni voce contiene il tipo di consenso, il momento della concessione, opzionalmente il momento della revoca, indirizzo IP, user agent e la versione del testo di consenso. La combinazione di ID utente e tipo di consenso è unica; un utente può avere solo un consenso attivo per tipo.
La tabella IntervieweeConsent è per i partecipanti alle interviste. Non sono utenti registrati, quindi non hanno un ID utente. Invece, colleghiamo il consenso all'ID di sessione. Inoltre, memorizziamo un hash SHA-256 del testo di consenso visualizzato. Questo ci permette di dimostrare in seguito esattamente quale testo ha visto il partecipante.
L'hook React useAiConsent rende la gestione del consenso utilizzabile nel frontend. Verifica al caricamento del componente se esiste già un consenso. In caso contrario, mostra un modale. Dopo la conferma, salva il consenso tramite l'API e ricorda lo stato per la sessione.
const { hasConsent, grantConsent, showConsentModal } = useAiConsent("import_questions")
// Prima di un'azione che richiede consenso:
if (!hasConsent) {
setShowConsentModal(true)
return
}
// Consenso esistente, procedere con l'azione
Per la revoca, non cancelliamo la voce di consenso ma impostiamo una data revokedAt. Il GDPR permette di conservare le prove di consenso anche dopo la revoca; fanno parte dell'obbligo di documentazione.
Trasparenza IA secondo l'EU AI Act
L'EU AI Act richiede da agosto 2025 che gli utenti siano informati quando interagiscono con un sistema IA. L'abbiamo costruito così fin dall'inizio.
Il ConsentDialog per i partecipanti alle interviste rende inequivocabilmente chiaro che un sistema IA conduce l'intervista. Il testo è disponibile in cinque lingue: tedesco, inglese, francese, spagnolo, italiano. Nessuna traduzione automatica, ma testi localizzati.
Il dialogo contiene tre informazioni centrali: I dati sono memorizzati in modo crittografato su un server tedesco. L'elaborazione è effettuata da modelli IA. I dati non vengono usati per l'addestramento dell'IA.
Oltre alla casella di consenso, c'è una verifica captcha. Questa non è un requisito del GDPR ma una protezione contro gli accessi automatizzati.
Nella dashboard, gli avvisi IA sono meno prominenti ma presenti. Un piccolo testo sopra la chat: "Analisi alimentata dall'IA". Nessun modale, nessun popup; l'utente sa senza essere interrotto.
Cancellazione automatica dei dati per periodo di conservazione
Stabilire periodi di conservazione è facile. Rispettarli è più difficile.
Il GDPR richiede nell'articolo 5 che i dati non siano conservati più a lungo del necessario. Sembra ovvio ma fallisce regolarmente nella pratica. Lo studio è finito, i dati sono ancora da qualche parte, nessuno se ne occupa.
Abbiamo impostato un cronjob che viene eseguito giornalmente alle 02:30. Controlla tre categorie: I ticket di supporto più vecchi di 24 mesi vengono cancellati. Le sessioni di intervista archiviate più vecchie di 12 mesi vengono cancellate. Le prove di consenso degli utenti cancellati vengono rimosse dopo 36 mesi.
Il job viene eseguito in modalità dry-run quando avviato manualmente. Mostra cosa verrebbe cancellato senza effettivamente cancellare. Solo con il flag --execute i dati vengono realmente rimossi.
| Tipo di dati | Periodo di conservazione | Cancellazione automatica |
|---|---|---|
| Ticket di supporto | 24 mesi | Sì |
| Sessioni archiviate | 12 mesi | Sì |
| Prove di consenso | 36 mesi dopo la cancellazione | Sì |
| Dati di progetto | Durata del progetto + 12 mesi | Alla cancellazione del progetto |
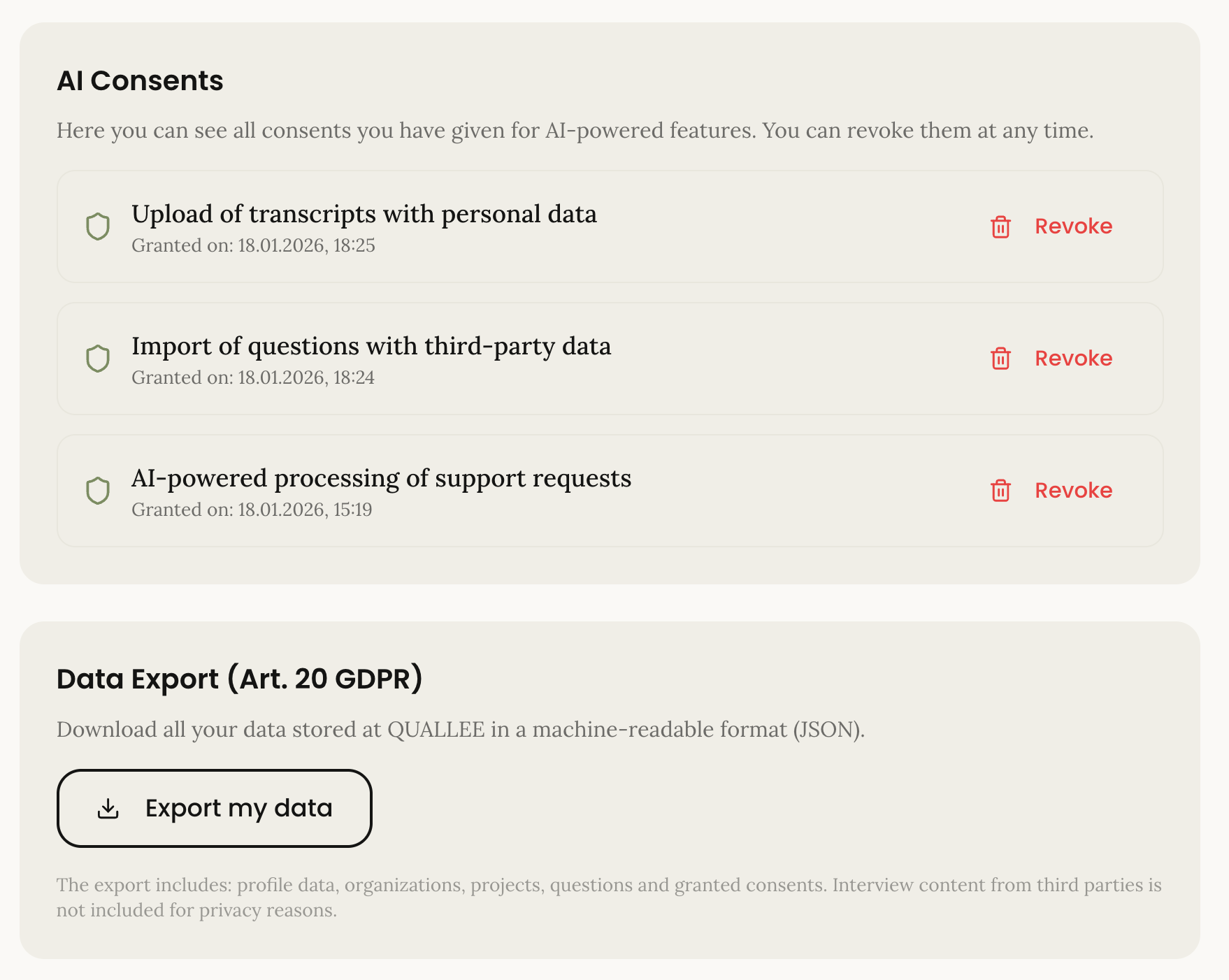
Diritti degli interessati come self-service
Il GDPR dà alle persone diritti sui propri dati: Accesso (Art. 15), Rettifica (Art. 16), Cancellazione (Art. 17), Portabilità (Art. 20). In molti prodotti, questi sono processi manuali: L'utente scrive un'email, qualcuno esporta manualmente i dati, li invia come file ZIP.
Per noi, sono funzionalità nelle impostazioni dell'account.
La pagina privacy mostra tutti i consensi concessi. Gli utenti possono revocarli individualmente. La revoca è facile quanto la concessione; è ciò che l'articolo 7(3) del GDPR richiede.
L'esportazione dei dati genera un file JSON con tutti i dati personali: Informazioni dell'account, progetti, consensi concessi. Leggibile dalla macchina, come richiede l'articolo 20.
La cancellazione dell'account è una cancellazione soft con anonimizzazione. Rimuoviamo i dati personali ma conserviamo i dati di progetto anonimizzati se rilevanti per altri membri del team. Le prove di consenso sono conservate; l'articolo 17(3) lo permette esplicitamente.
Cosa abbiamo imparato da questo
Privacy by Design richiede tempo. Costruire l'infrastruttura di consenso ha richiesto più tempo di un semplice banner dei cookie. La cancellazione automatica richiede più pianificazione di "cancelleremo quando qualcuno si lamenta".
Questo investimento ripaga, non principalmente attraverso le multe evitate (sebbene le sanzioni GDPR abbiano superato i 2 miliardi di euro nel 2025), ma attraverso la fiducia. I ricercatori lavorano con dati sensibili. Vogliono sapere che i loro partecipanti sono protetti. Un concetto di protezione dei dati tracciabile è un argomento di vendita.
L'EU AI Act ha alzato i requisiti, non li ha cambiati. Chi costruisce i propri prodotti IA in modo trasparente e con parsimonia di dati fin dall'inizio non dovrà affrettarsi ad agosto 2026.
Domande frequenti
Cos'è Privacy by Design?
Privacy by Design è un concetto della Dott.ssa Ann Cavoukian che chiede di integrare la protezione dei dati nello sviluppo dei sistemi fin dall'inizio, piuttosto che aggiungerla dopo. Il GDPR l'ha sancito nell'articolo 25 come "protezione dei dati fin dalla progettazione e per impostazione predefinita".
Come si differenzia un avviso informativo dal consenso esplicito?
Un avviso informativo è sufficiente per l'esecuzione del contratto (Art. 6(1)(b) GDPR) quando l'utente stesso è parte del contratto. Il consenso esplicito con memorizzazione è richiesto quando vengono trattati dati di terzi o l'interessato non è parte del contratto.
Per quanto tempo devono essere conservate le prove di consenso?
Il GDPR non specifica un periodo concreto, ma le aziende devono poter dimostrare che il consenso è stato dato. Si raccomandano 3 anni dopo la revoca o la fine del contratto, corrispondenti al termine di prescrizione civile.
I miei dati vengono usati per addestrare l'IA?
No. Sia OpenAI che Anthropic hanno firmato Accordi per il Trattamento dei Dati che escludono l'uso dei dati API per l'addestramento dei modelli. I dati grezzi rimangono su server tedeschi.
Prova tu stesso
QUALLEE conduce interviste alimentate dall'IA che sono conformi fin dall'inizio. Server tedeschi, DPA documentati, periodi di conservazione automatici, processi di consenso trasparenti. Un'intervista dura circa 20-30 minuti.