
Privacy by Design signifie intégrer la protection des données dans l'architecture logicielle dès le départ, et non l'ajouter après coup. Chez QUALLEE, cela comprend : une gestion granulaire du consentement avec piste d'audit, la suppression automatique des données selon des durées de conservation définies, le libre-service pour les droits des personnes concernées et une transparence totale sur le traitement par IA. Cet article présente la mise en œuvre technique concrète.
Pourquoi la protection des données est une question d'architecture
La plupart des logiciels traitent la protection des données comme une liste de contrôle à cocher avant le lancement. Une bannière de cookies ici, une politique de confidentialité là, peut-être une fenêtre de consentement. Terminé.
Jusqu'à ce que quelqu'un demande où exactement le consentement est stocké. Jusqu'à ce qu'un utilisateur veuille exporter ses données. Jusqu'à ce que le régulateur veuille savoir combien de temps quelles données sont conservées et pourquoi.
Ajouter la protection des données après coup coûte plus cher que de l'intégrer dès le départ. C'était le raisonnement lorsque nous avons construit QUALLEE. Privacy by Design n'est pas une philosophie ; c'est une décision architecturale que l'on prend au début ou que l'on paie pour corriger plus tard.
Les sept principes d'Ann Cavoukian
Dr. Ann Cavoukian a formulé Privacy by Design dans les années 90. Sept principes reconnus comme standard par les autorités internationales de protection des données en 2010. Le RGPD les a adoptés dans l'article 25.
Les principes semblent abstraits : « Proactif et non réactif », « Confidentialité par défaut », « Sécurité de bout en bout ». En pratique, ils signifient des décisions concrètes.
Proactif et non réactif signifie : Avant de construire une fonctionnalité, nous nous demandons quelles données elle nécessite et pour combien de temps. Pas quand quelqu'un demande les durées de conservation.
Confidentialité par défaut signifie : Si un utilisateur ne fait rien, ses données sont quand même protégées. Pas de pièges d'opt-out, pas de cases marketing précochées.
Confidentialité intégrée dans la conception signifie : La protection des données n'est pas un composant qu'on active ou désactive. Elle est dans le schéma de base de données, dans les endpoints API, dans les composants UI.
Les produits IA et le problème de confiance
Les produits IA ont un problème d'image en matière de protection des données. Les gros titres sur les données d'entraînement, sur les modèles reproduisant des informations personnelles, sur les flux de données opaques ont laissé des traces.
Le problème est réel, mais pas inévitable. Les produits alimentés par l'IA peuvent être conformes ; ils nécessitent simplement plus de soin dans l'architecture.
Chez QUALLEE, les données d'entretien passent par des modèles d'IA d'Anthropic et OpenAI. C'est le cœur du produit. En même temps, nous avons tracé des limites claires.
Les données brutes restent sur nos serveurs en Allemagne. Seul le contenu textuel nécessaire à l'analyse est envoyé aux API d'IA, transmis de manière chiffrée. Les deux fournisseurs ont signé des accords de traitement des données qui excluent l'utilisation pour l'entraînement des modèles. Nous avons documenté et classé les DPA d'OpenAI, Anthropic, Hetzner, Stripe et Resend.
L'IA analyse ce que les gens disent ; elle n'analyse pas leur apparence. Pas de reconnaissance faciale, pas de détection d'émotion à partir de vidéo ou audio. Cela est interdit dans certains contextes depuis février 2025 par le EU AI Act, mais nous l'avons construit ainsi dès le départ.
Gestion du consentement selon l'article 6 du RGPD
Le RGPD distingue différentes bases juridiques pour le traitement des données. L'article 6 les énumère. Deux sont particulièrement pertinentes pour nous : l'exécution du contrat et le consentement.
Lorsqu'un client payant utilise le chat d'analyse, nous traitons ses données sur la base de l'exécution du contrat. Il s'est abonné, l'analyse fait partie du contrat. Un avis indiquant que l'IA est utilisée suffit. Pas de modale, pas de case à cocher, pas de stockage.
C'est différent lorsque des données de tiers entrent en jeu. Lorsqu'un chercheur télécharge des transcriptions contenant des déclarations de participants à des entretiens. Ou lorsque quelqu'un importe des questions clés qui peuvent contenir des informations personnelles. Ici, nous avons besoin d'un consentement explicite, et nous devons le stocker.
La distinction semble académique mais a des conséquences pratiques. Un avis d'information est une phrase de texte dans l'UI. Un consentement stocké est une entrée de base de données avec horodatage, adresse IP, user agent et numéro de version du texte de consentement.
| Emplacement | Ce qui est requis | Justification |
|---|---|---|
| Chat d'analyse | Avis d'information | L'utilisateur est partie au contrat |
| Chat de support | Avis d'information | Exécution du contrat |
| Import de questions | Consentement + stockage | Données de tiers possibles |
| Téléchargement de transcriptions | Consentement + stockage | Données de tiers (participants) |
| Participation à l'entretien | Consentement + stockage | Le participant n'est pas partie au contrat |
Mise en œuvre technique de la gestion du consentement
La gestion du consentement nécessite une infrastructure. Pour nous, ce sont deux tables de base de données, plusieurs endpoints API et un hook React.
La table UserAiConsent stocke les consentements des utilisateurs enregistrés. Chaque entrée contient le type de consentement, le moment de l'octroi, optionnellement le moment de la révocation, l'adresse IP, le user agent et la version du texte de consentement. La combinaison ID utilisateur et type de consentement est unique ; un utilisateur ne peut avoir qu'un seul consentement actif par type.
La table IntervieweeConsent est pour les participants aux entretiens. Ce ne sont pas des utilisateurs enregistrés, donc ils n'ont pas d'ID utilisateur. À la place, nous lions le consentement à l'ID de session. De plus, nous stockons un hash SHA-256 du texte de consentement affiché. Cela nous permet de prouver plus tard exactement quel texte le participant a vu.
Le hook React useAiConsent rend la gestion du consentement utilisable dans le frontend. Il vérifie au chargement du composant si un consentement existe déjà. Sinon, il affiche une modale. Après confirmation, il enregistre le consentement via l'API et mémorise le statut pour la session.
const { hasConsent, grantConsent, showConsentModal } = useAiConsent("import_questions")
// Avant une action nécessitant un consentement :
if (!hasConsent) {
setShowConsentModal(true)
return
}
// Consentement existant, procéder à l'action
Pour la révocation, nous ne supprimons pas l'entrée de consentement mais définissons une date revokedAt. Le RGPD permet de conserver les preuves de consentement même après révocation ; elles font partie de l'obligation de documentation.
Transparence IA selon l'EU AI Act
L'EU AI Act exige depuis août 2025 que les utilisateurs soient informés lorsqu'ils interagissent avec un système d'IA. Nous l'avons construit ainsi dès le départ.
Le ConsentDialog pour les participants aux entretiens indique clairement qu'un système d'IA conduit l'entretien. Le texte est disponible en cinq langues : allemand, anglais, français, espagnol, italien. Pas de traduction automatique, mais des textes localisés.
Le dialogue contient trois informations centrales : Les données sont stockées de manière chiffrée sur un serveur allemand. Le traitement est effectué par des modèles d'IA. Les données ne sont pas utilisées pour l'entraînement de l'IA.
En plus de la case de consentement, il y a une vérification captcha. Ce n'est pas une exigence du RGPD mais une protection contre les accès automatisés.
Dans le tableau de bord, les avis IA sont moins proéminents mais présents. Un petit texte au-dessus du chat : « Analyse alimentée par l'IA ». Pas de modale, pas de popup ; l'utilisateur sait sans être interrompu.
Suppression automatique des données selon les durées de conservation
Définir des durées de conservation est facile. Les respecter est plus difficile.
Le RGPD exige dans l'article 5 que les données ne soient pas conservées plus longtemps que nécessaire. Cela semble évident mais échoue régulièrement en pratique. L'étude est terminée, les données sont encore quelque part, personne ne s'en occupe.
Nous avons mis en place un cronjob qui s'exécute quotidiennement à 02h30. Il vérifie trois catégories : Les tickets de support de plus de 24 mois sont supprimés. Les sessions d'entretien archivées de plus de 12 mois sont supprimées. Les preuves de consentement des utilisateurs supprimés sont retirées après 36 mois.
Le job s'exécute en mode dry-run lorsqu'il est lancé manuellement. Il montre ce qui serait supprimé sans réellement supprimer. Ce n'est qu'avec le flag --execute que les données sont réellement supprimées.
| Type de données | Durée de conservation | Suppression automatique |
|---|---|---|
| Tickets de support | 24 mois | Oui |
| Sessions archivées | 12 mois | Oui |
| Preuves de consentement | 36 mois après suppression | Oui |
| Données de projet | Durée du projet + 12 mois | À la suppression du projet |
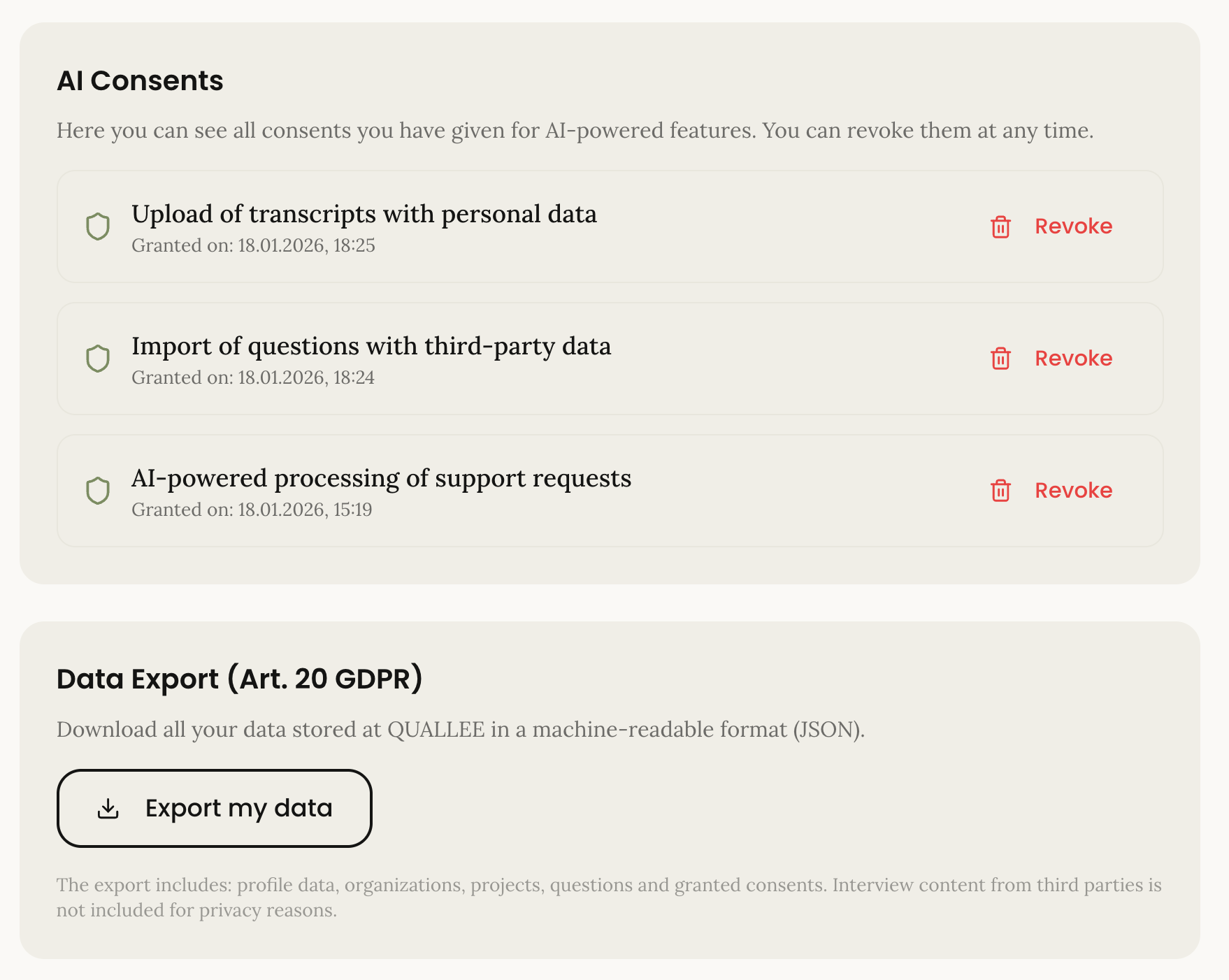
Droits des personnes concernées en libre-service
Le RGPD donne aux personnes des droits sur leurs données : Accès (Art. 15), Rectification (Art. 16), Effacement (Art. 17), Portabilité (Art. 20). Dans beaucoup de produits, ce sont des processus manuels : L'utilisateur écrit un email, quelqu'un exporte manuellement les données, les envoie en fichier ZIP.
Pour nous, ce sont des fonctionnalités dans les paramètres du compte.
La page de confidentialité affiche tous les consentements accordés. Les utilisateurs peuvent les révoquer individuellement. La révocation est aussi facile que l'octroi ; c'est ce que l'article 7(3) du RGPD exige.
L'export de données génère un fichier JSON avec toutes les données personnelles : Informations de compte, projets, consentements accordés. Lisible par machine, comme l'exige l'article 20.
La suppression de compte est une suppression douce avec anonymisation. Nous supprimons les données personnelles mais conservons les données de projet anonymisées si elles sont pertinentes pour d'autres membres de l'équipe. Les preuves de consentement sont conservées ; l'article 17(3) le permet explicitement.
Ce que nous avons appris
Privacy by Design prend du temps. Construire l'infrastructure de consentement a pris plus de temps qu'une simple bannière de cookies. La suppression automatique nécessite plus de planification que « nous supprimerons quand quelqu'un se plaindra ».
Cet investissement est rentable, pas principalement par les amendes évitées (bien que les pénalités RGPD aient dépassé 2 milliards d'euros en 2025), mais par la confiance. Les chercheurs travaillent avec des données sensibles. Ils veulent savoir que leurs participants sont protégés. Un concept de protection des données traçable est un argument de vente.
L'EU AI Act a augmenté les exigences, pas les a changées. Ceux qui construisent leurs produits IA de manière transparente et économe en données dès le départ n'auront pas à se précipiter en août 2026.
Questions fréquemment posées
Qu'est-ce que Privacy by Design ?
Privacy by Design est un concept du Dr. Ann Cavoukian qui appelle à intégrer la protection des données dans le développement des systèmes dès le départ, plutôt que de l'ajouter après. Le RGPD l'a consacré dans l'article 25 comme « protection des données dès la conception et par défaut ».
Quelle différence entre un avis d'information et un consentement explicite ?
Un avis d'information suffit pour l'exécution du contrat (Art. 6(1)(b) RGPD) lorsque l'utilisateur lui-même est partie au contrat. Un consentement explicite avec stockage est requis lorsque des données de tiers sont traitées ou que la personne concernée n'est pas partie au contrat.
Combien de temps les preuves de consentement doivent-elles être conservées ?
Le RGPD ne spécifie pas de période concrète, mais les entreprises doivent pouvoir prouver que le consentement a été donné. 3 ans après révocation ou fin de contrat est recommandé, correspondant au délai de prescription civil.
Mes données sont-elles utilisées pour l'entraînement de l'IA ?
Non. OpenAI et Anthropic ont tous deux signé des accords de traitement des données qui excluent l'utilisation des données API pour l'entraînement des modèles. Les données brutes restent sur des serveurs allemands.
Essayez par vous-même
QUALLEE mène des entretiens alimentés par l'IA qui sont conformes dès le départ. Serveurs allemands, DPA documentés, durées de conservation automatiques, processus de consentement transparents. Un entretien dure environ 20 à 30 minutes.